Мониторинг состояния узлов при помощи Prometheus и Grafana
В этом разделе описано, как настроить процесс контроля и отслеживания различных метрик и параметров работы узлов (серверов), на которые установлена Платформа, с использованием программных инструментов Prometheus и Grafana.
Подготовительные действия
Для подготовки к настройке процесса мониторинга следует установить последние версии docker и docker-compose (необходимо установить самостоятельные исполняемые файлы docker и docker-compose, а не интегрировать их как плагины в существующую установку docker):
# устанавливаем подготовительные компоненты и подключаем ключи для репозитория
apt-get update
apt-get install ca-certificates curl gnupg
install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg
chmod a+r /etc/apt/keyrings/docker.gpg
# добавляем репозиторий для docker-а
sudo vim /etc/apt/sources.list.d/docker.list
# добавляем репозиторий
deb [arch=amd64 signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian buster stable
# обновляем кэш и устанавливаем docker и все компоненты
apt update
apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin
# устанавливаем docker-compose отдельным исполняемым файлом; на момент написания инструкции актуальной версией является 2.23.0
curl -SL https://github.com/docker/compose/releases/download/v2.23.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
Запуск компонентов
Далее следует запустить необходимые компоненты:
Создайте файл docker-compose.yml, содержащий следующие сервисы:
version: '3.9' services: prometheus: image: prom/prometheus:latest volumes: - ./prometheus/configuration/:/etc/prometheus/ - ./prometheus/data/:/prometheus/ container_name: prometheus hostname: prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--web.enable-admin-api' - '--web.enable-lifecycle' ports: - 9090:9090 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - default node-exporter: image: prom/node-exporter volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro container_name: exporter hostname: exporter command: - --path.procfs=/host/proc - --path.sysfs=/host/sys - --collector.filesystem.ignored-mount-points - ^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/) ports: - 9100:9100 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - default grafana: image: grafana/grafana user: root depends_on: - prometheus ports: - 3000:3000 volumes: - ./grafana:/var/lib/grafana - ./grafana/provisioning/:/etc/grafana/provisioning/ container_name: grafana hostname: grafana restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - default networks: default: ipam: driver: default config: - subnet: 172.28.0.0/16Данный файл содержит:
сервис prometheus
сервис prometheus-node-exporter
сервис grafana
сеть default (172.28.0.0/16)
Все контейнеры запускаются с IP-адресами из указанного в default-диапазона. Этот диапазон указывается после параметра subnet (он находится в самой последней строке представленного выше содержания файла docker-compose.yml). В данном случае диапазон 172.28.0.0/16 означает, что у запускаемых контейнеров будут IP-адреса, начинающиеся с 172.28.0.0 и заканчивается на 172.28.255.255.
В директории, содержащей файл docker-compose.yml, необходимо создать файловую структуру и базовые конфигурационные файлы для Prometheus:
mkdir -p prometheus/configuration/ mkdir -p prometheus/data/ # выдаём права для записи в папку данных prometheus chown 65534:65534 prometheus/data/ # создаём конфигурационный файл для сбора метрик с с сервиса prometheus-node-exporter cat << EOF >> prometheus/configuration/prometheus.yml scrape_configs: - job_name: node scrape_interval: 5s static_configs: - targets: ['node-exporter:9100'] EOF
Запустите docker-compose из каталога, в котором находится созданный файл docker-compose.yml:
docker-compose up -dПри запуске из иного каталога необходимо указать путь к созданному файлу docker-compose.yml при помощи флага -f :
docker-compose -f <path_to_docker-compose.yml_file> up -dУспешной индикацией запуска docker-compose служит появление трёх контейнеров:
prometheus
exporter
grafana
Проверить их наличие можно с помощью следующий команды:
docker container ps -aВ результате вы получите информацию обо всех запущенных контейнерах в docker:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 2cae7b16d140 prom/prometheus:latest "/bin/prometheus --c…" 1 minute ago 1 minute ago 0.0.0.0:9090->9090/tcp prometheus b67cb56199ff grafana/grafana "/run.sh" 1 minute ago 1 minute ago 0.0.0.0:3000->3000/tcp grafana 01eb08aa5db9 prom/node-exporter "/bin/node_exporter …" 1 minute ago 1 minute ago 0.0.0.0:9100->9100/tcp exporterЗдесь отображаются:
CONTAINER ID - идентификатор контейнера
IMAGE - использованный образ
COMMAND - команда для запуска контейнера
CREATED - время создания контейнера
STATUS - статус контейнера
PORTS - использованные порты
В файле docker-compose.yml есть два сервиса, имеющие полноценный графический интерфейс: Grafana и Prometheus. Они доступны по адресам:
Настройка Prometheus
После запуска компонентов, в каталоге, из которого запускался docker-compose.yml файл, создадутся две директории:
grafana - в этом каталоге будут храниться создаваемые дашборды и метрики;
- prometheus - в этой директории будут два каталога:
configuratio - здесь будет храниться конфигурационный файл prometheus.yml;
data - этот каталог будет содержать данные самого prometheus.
Настройка Prometheus будет представлять следующий алгоритм:
Для того чтобы добавить метрики по мониторингу состояния узлов для сбора через Prometheus необходимо отредактировать файл prometheus/configuration/prometheus.yml:
scrape_configs: - job_name: node scrape_interval: 5s static_configs: - targets: ['node-exporter:9100'] # для добавления новой задачи (job) по сбору метрик создайте новый элемент - job_name: some_name_here scrape_interval: 5s static_configs: - targets: - target1:9100 - targetN:9100 # в рамках одной задачи (job) можно собирать метрики с разных узлов. Иногда это бывает полезно для построения дашбордов;Конфигурационный файл prometheus.yml содержит множество других настроек. Информацию о них можно найти в официальной документации.
После добавления или изменения файла prometheus.yml необходимо отправить запрос в контейнер для перечитывания файла (для учёта новых изменений). Для этого из каталога, содержащего файл docker-compose.yml (с помощью которого запускался сервис prometheus) необходимо выполнить команду:
docker-compose kill -s SIGHUP prometheus
Удаление метрик Prometheus
В процессе работы могут возникать случаи, когда надо очистить какие-то данные в Prometheus. Например, когда при сборе метрик одна и та же информация собирается по-разному и в дашбордах начинаются коллизии или неправильное отображение информации. Примеры команд, представленных ниже, основаны на запуске Prometheus через файл docker-compose.yml со всеми настройками (в особенности настройками портов и флагов запуска).
При запуске Prometheus иным методом добавьте возможность администратора работы с API и проверьте порт запуска сервиса (в данном примере это порт 9090).
Для удаления всех метрик, которые относятся к определённой метке (например, foo=bar) используется команда:
curl -X POST \ -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={foo="bar"}'
Для удаления метрик по задаче (job) или по экземпляру используются команды:
curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={job="node_exporter"}' curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={instance="192.168.0.1:9100"}'
После удаления данных из Prometheus дашборды Grafana будут наполняться в соответствии с параметром scrape_interval, указанным в каждой задаче (job) Prometheus’а (эти задачи можно найти в файле prometheus.yml, находящемся в каталоге prometheus/configuration/).
Настройка Grafana
Настройку Grafana можно проводить как через графический интерфейс (добавляя или меняя дашборды), так и путём редактирования файлов в каталоге Grafana, созданном в директории, содержащей файл docker-compose.yml, с помощью которого запускали настроенный в этом файле контейнер. Результаты выполнения команд ниже могут отличаться от приведённых на скриншотах примеров и показывать примерное отображение метрик. Детальная настройка (формат отображаемой метрики, частота обновления и прочие параметры) производится пользователями индивидуально в зависимости от потребностей.
При обращении к порту http://<IP_узла_установки>:3000 откроется авторизационное меню Grafana:
Для первого входа используйте данные:
login: admin
password: admin
При первом успешном входе система предложит их сменить.
Для добавления источника данных (в данном случае это Prometheus) выполните следующую последовательность шагов:
Откройте панель меню, находящуюся в левом верхнем углу страницы (цифра 1 на рисунке ниже).
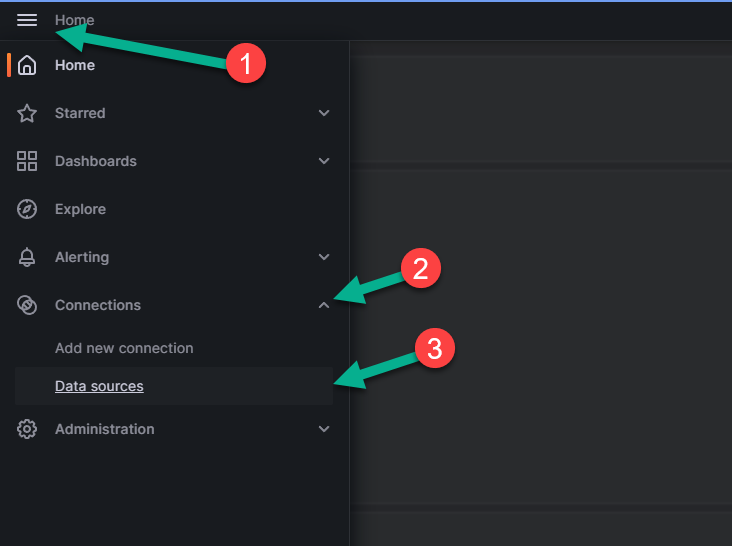
Нажав на стрелку рядом с пунктом «Connections» («Соединения»), раскройте подпункты этой опции (цифра 2 на рисунке выше).
Кликните на опцию «Data sources» («Источники данных»), обозначенную цифрой 3 на рисунке выше. Откроется следующая страница:
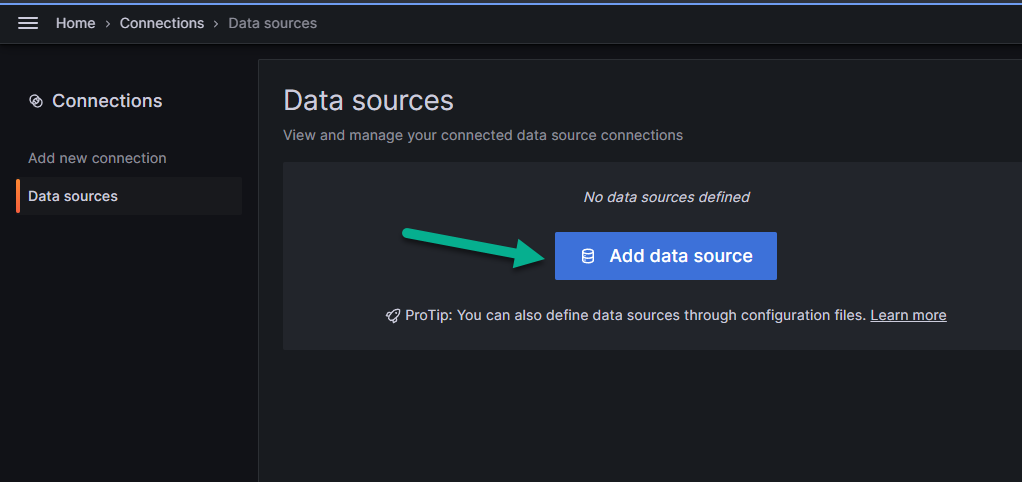
Нажмите на кнопку «Add data source» («Добавить источник данных»), показанную на рисунке выше.
В высветившемся меню найдите Prometheus и выберите его, нажав на него.
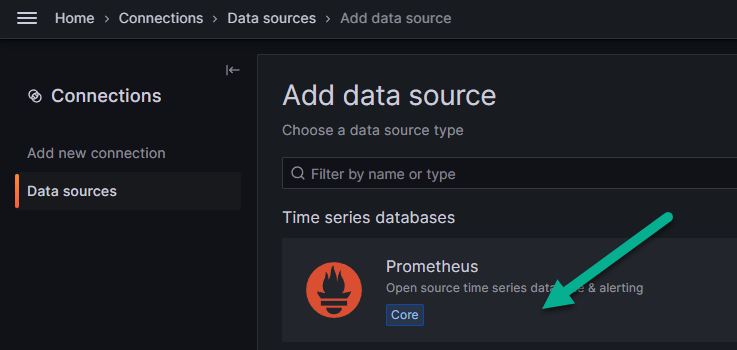
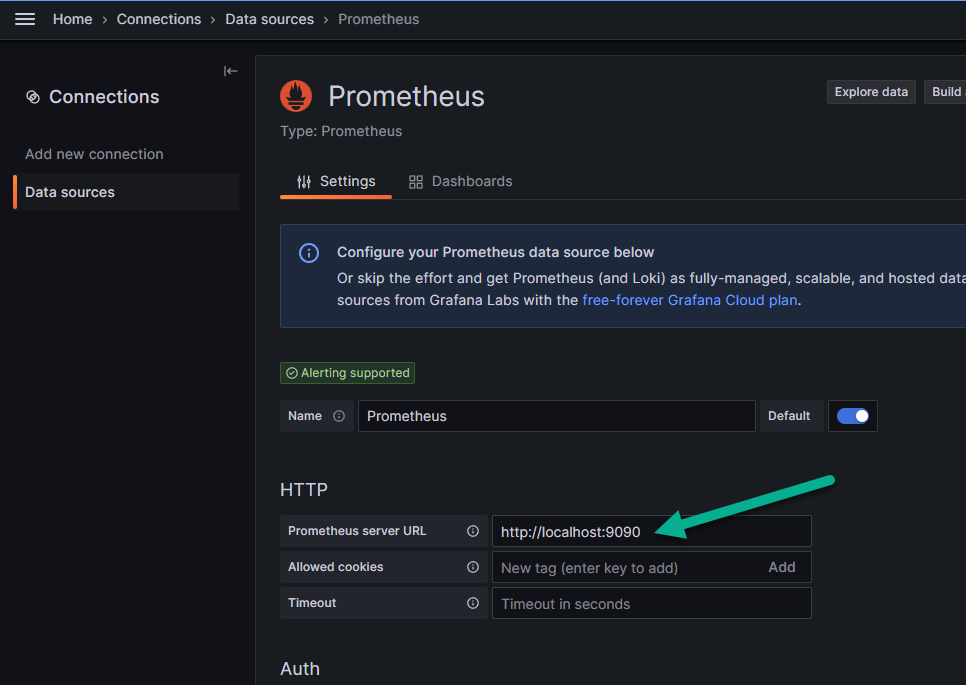
Во вкладке «Settings» («Настройки») в текстовое поле «Prometheus server URL», показанное стрелкой на рисунке ниже, введите IP-адрес узла, на котором развёрнут Prometheus. Итоговое значение должно иметь вид: http://<IP_узла_установки>:9090
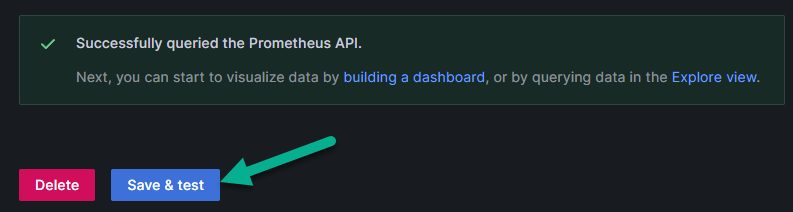
Нажмите на кнопку «Save & test» («Сохранить и проверить»), поле чего пройдёт тестирование подключения и в случае успешного подключения к источнику данных Prometheus появится оповещение, показанное на рисунке ниже.
После добавления источника данных необходимо настроить дашборды для отображения информации. Для добавления дашборда выполните следующие действия:
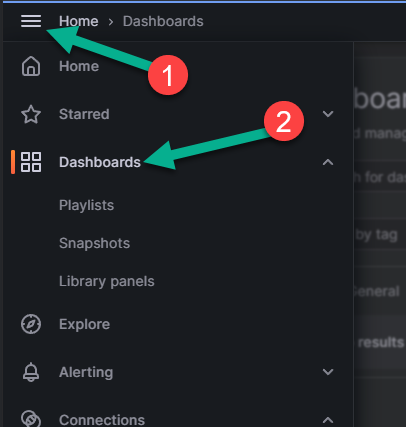
Откройте панель меню, находящуюся в левом верхнем углу страницы (цифра 1 на рисунке ниже).
Выберите пункт меню «Dashboards» («Дашборды»), обозначенный цифрой 2 на рисунке ниже.
На появившейся странице нажмите на кнопку «New» (цифра 1 на рисунке ниже).
В выпавшем меню выберите пункт»Import» (цифра 2 на рисунке ниже).
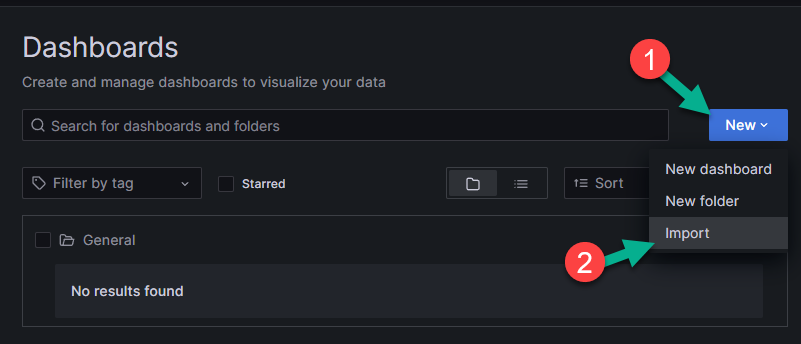
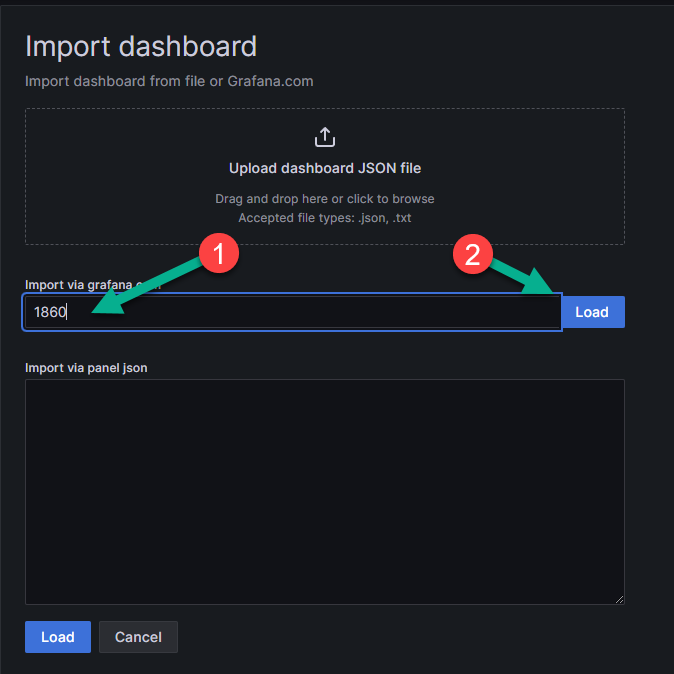
В текстовое поле (цифра 1 на рисунке ниже) введите дашборд, который собираетесь импортировать. В данном примере 1860 - это собранный дашборд для Node Exporter. Примеры готовых дашбордов можно найти на официальном сайте.
Нажмите на кнопку «Load» («Загрузить») для загрузки дашборда (цифра 2 на рисунке ниже). Также дашборд можно импортировать, вставив в нижнее текствое поле JSON-код. После загрузки дашборда удобным вам способом ещё раз нажмите на кнопку «Load», находящуюся внизу окна.
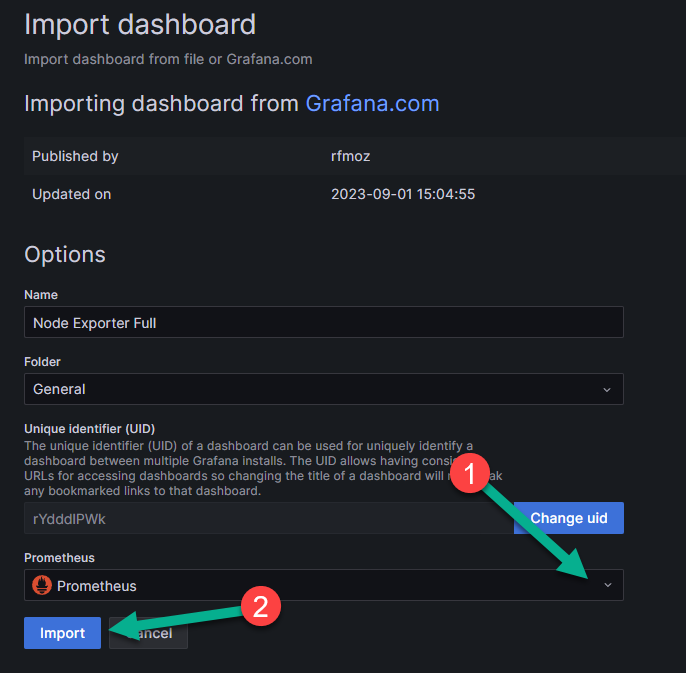
На появившейся странице финального импорта в поле «Folder» («Папка») можно будет выбрать папку, в которой будет отображаться импортируемый дашборд. По умолчанию это будет папка «General», созданная автоматически.
В выпадающем списке (цифра 1 на рисунке ниже) укажите Prometheus.
Нажмите на кнопку «Import» для финального импорта дашборда (цифра 2 на рисунке ниже).
Зайдя на страницу Dashboards после добавления дашборда, можно увидеть, что он отображается в выбранной на странице финального импорта папке (в данном примере это папка «General»).
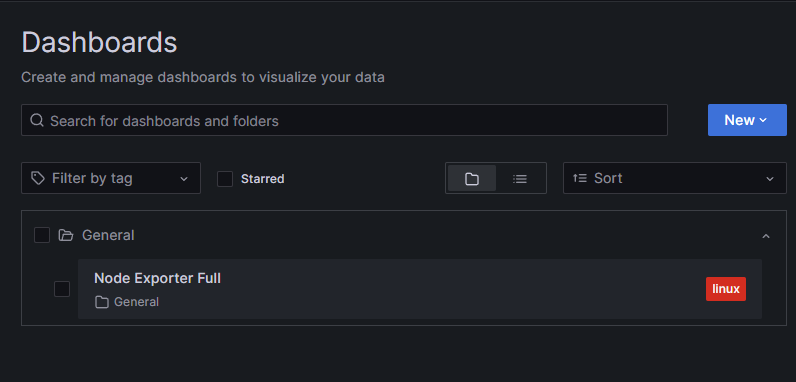
При переходе на импортированный дашборд откроется страница с данными по нему:
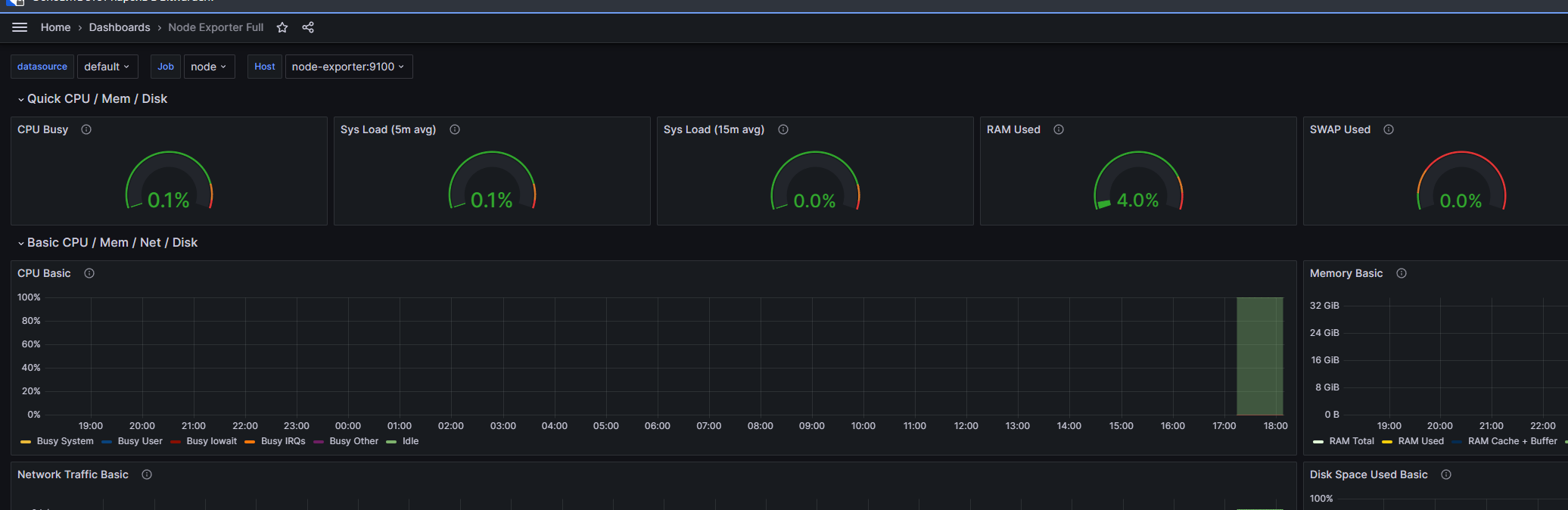
Мониторинг NATS
На всех узлах, где устанавливается NATS-сервер, он открывает порт 8222, на который открывает ряд метрик. Эти метрики можно обрабатывать при помощи соответствующего exporter’а.
Для подключения NATS к мониторингу при помощи Prometheus выполните следующие действия:
запустите NATS-экспортер (можно воспользоваться официальной документацией для запуска exporter’а в виде сервиса, либо запустить его при помощи docker-compose, используя пример выше:
version: '3.9'
services:
prometheus-nats-exporter:
image: natsio/prometheus-nats-exporter:latest
container_name: prometheus-nats-exporter
hostname: prometheus-nats-exporter
command: "-connz -gatewayz -healthz -jsz all -subz -leafz -routez -varz http://<host_IP_with_installed_nats_server>:8222"
ports:
- 7777:7777
restart: unless-stopped
environment:
TZ: "Europe/Moscow"
networks:
- default
networks:
default:
ipam:
driver: default
config:
- subnet: 172.28.0.0/16
У NATS есть различные метрики, которые может собирать nats-exporter. Необходимо перейти по адресу http://<host_IP_with_installed_nats_server>:8222 и, нажимая на ссылки, найти необходимый набор метрик, по которым нужно проводить мониторинг. После этого необходимо обратиться к официальной документации и найти нужные для этих метрик флаги.
Например, NATS-сервер отдаёт состояние JetStream по ссылке http://<host_IP_with_installed_nats_server>:8222/jsz/metrics. Чтобы метрики начали обрабатываться exporter’ом, нужно добавить -jsz all в качестве флага в директиву command (как показано в примере файла docker-compose.yml выше).
запустите сервис при помощи docker-compose из каталога с созданным файлом docker-compose.yml:
docker-compose up -d
проверьте, что nats-exporter отдаёт метрики для prometheus-сервера на порту, определённом в директиве ports (в примере выше это порт 7777):
curl http://<host_IP_with_installed_nats_server>:7777/metrics
Полученный ответ будет содержать метрики, описывающие состояние сервера:
... # HELP jetstream_server_jetstream_disabled JetStream disabled or not # TYPE jetstream_server_jetstream_disabled gauge jetstream_server_jetstream_disabled{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 0 # HELP jetstream_server_max_memory JetStream Max Memory # TYPE jetstream_server_max_memory gauge jetstream_server_max_memory{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 1.554736128e+09 # HELP jetstream_server_max_storage JetStream Max Storage # TYPE jetstream_server_max_storage gauge jetstream_server_max_storage{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 1.402610688e+10 # HELP jetstream_server_total_consumers Total number of consumers in JetStream # TYPE jetstream_server_total_consumers gauge jetstream_server_total_consumers{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 0 # HELP jetstream_server_total_message_bytes Total number of bytes stored in JetStream # TYPE jetstream_server_total_message_bytes gauge jetstream_server_total_message_bytes{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 0 # HELP jetstream_server_total_messages Total number of stored messages in JetStream # TYPE jetstream_server_total_messages gauge jetstream_server_total_messages{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 0 # HELP jetstream_server_total_streams Total number of streams in JetStream # TYPE jetstream_server_total_streams gauge jetstream_server_total_streams{cluster="tantor",domain="",is_meta_leader="false",meta_leader="devops-nats-3.tantorlabs.ru",server_id="http://10.128.0.69:8222",server_name="devops-nats-1.tantorlabs.ru"} 0 # HELP process_cpu_seconds_total Total user and system CPU time spent in seconds. # TYPE process_cpu_seconds_total counter process_cpu_seconds_total 0.53 # HELP process_max_fds Maximum number of open file descriptors. # TYPE process_max_fds gauge process_max_fds 1.048576e+06 # HELP process_open_fds Number of open file descriptors. # TYPE process_open_fds gauge ...
подключите дашборды 14725 и 2279, как описано в разделе Настройка Grafana.
проверьте наличие данных в дашбордах.
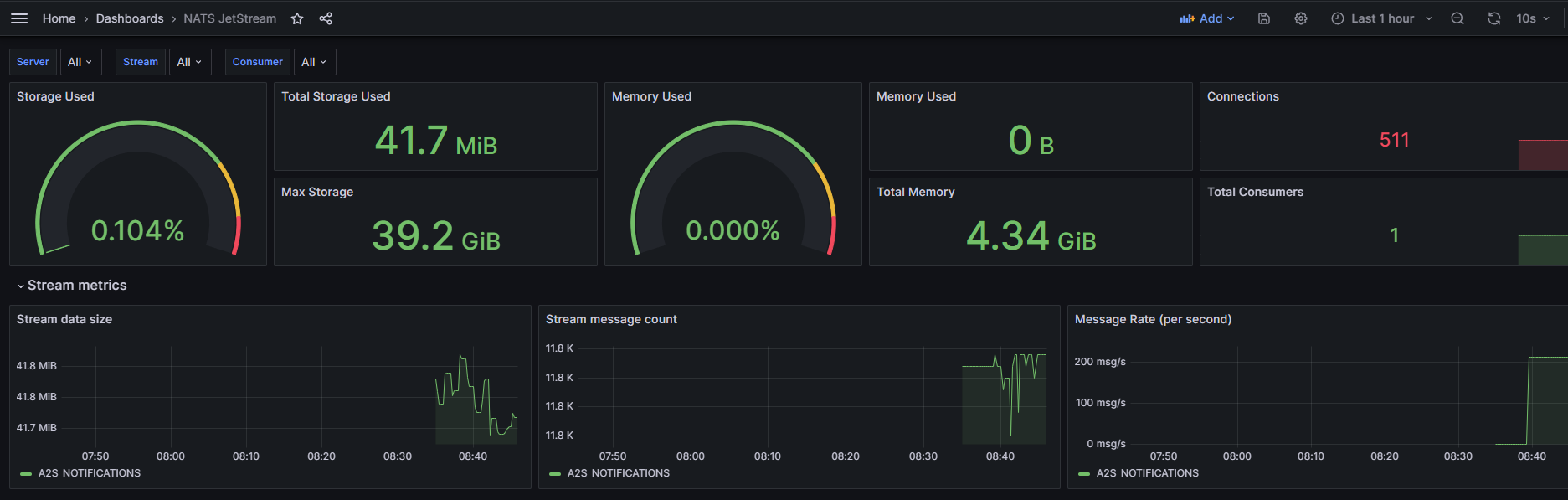
Мониторинг PostgreSQL
Для подключения PostgreSQL к мониторингу при помощи Prometheus необходимо выполнить следующие шаги:
создайте файл docker-compose.yml на узле, на котором есть необходимость осуществлять мониторинг PostgreSQL:
version: "3.9" services: postgres_exporter: container_name: postgres_exporter image: prometheuscommunity/postgres-exporter environment: DATA_SOURCE_URI: "<IP_of_host_with_PostgreSQL>:<PostgreSQL_port>/<PostgreSQL_database>?sslmode=disable" DATA_SOURCE_USER: "<user_that_has_access_to_db_above>" DATA_SOURCE_PASS: "<password_from_user_with_access_to_db>" PG_EXPORTER_EXTEND_QUERY_PATH: "/etc/postgres_exporter/queries.yaml" volumes: - ./queries.yaml:/etc/postgres_exporter/queries.yaml:ro ports: - "9187:9187" restart: unless-stopped deploy: resources: limits: cpus: '0.2' memory: 500M networks: - default networks: default: ipam: driver: default config: - subnet: 172.28.0.0/16
в этой же директории создайте файл queries.yaml. В нём описываются кастомные запросы (запросы, которые пользователь создает и оптимизирует самостоятельно для выполнения определенных задач) для PostgreSQL:
backend_rest_ip: master: true cache_seconds: 30 query: "select * from sys.base_config bc where bc.name='backend_rest'" metrics: - id: usage: "COUNTER" description: "id description is here" - key: usage: "LABEL" description: "key desc is here" - name: usage: "LABEL" description: "name description is here" - value: usage: "LABEL" description: "value description is here" - description: usage: "LABEL" description: "description is here" # пример других запросов error_count_in_logfile: master: true cache_seconds: 30 query: select count(*) from monitoring.v_logs; metrics: - count: usage: "COUNTER" description: "Количество ошибок в логе" metric_count_for_trigger: master: true cache_seconds: 30 query: select count(*) from monitoring.v_metric_triggers; metrics: - count: usage: "COUNTER" description: "Количество метрик для триггеров" latest_entry: master: true cache_seconds: 30 query: select metric_ts from monitoring.cv_metric_pg_stat_statements_sum order by metric_ts desc limit 1; metrics: - metric_ts: usage: "COUNTER" description: "Самая старая запись (проверка работы TTL)" top5_workers_with_errors: master: true cache_seconds: 30 query: select * from pipelinedb.proc_query_stats order by errors desc limit 5; metrics: - type: usage: "LABEL" - pid: usage: "LABEL" - start_time: usage: "LABEL" - query_id: usage: "LABEL" - input_rows: usage: "LABEL" - output_rows: usage: "LABEL" - updated_bytes: usage: "LABEL" - input_bytes: usage: "LABEL" - executions: usage: "LABEL" - errors: usage: "COUNTER" - exec_ms: usage: "LABEL" top5_streams_data_size: master: true cache_seconds: 30 #query: select namespace, stream, input_rows, pg_size_pretty(input_bytes) from pipelinedb.stream_stats order by input_bytes desc limit 5; query: select namespace, stream, input_bytes from pipelinedb.stream_stats order by input_bytes desc limit 5; metrics: - namespace: usage: "LABEL" - stream: usage: "LABEL" - input_bytes: usage: "COUNTER" backend_rest_ip: master: true cache_seconds: 30 query: select * from sys.base_config bc where bc.name='backend_rest'; metrics: - id: usage: "COUNTER" - key: usage: "LABEL" - name: usage: "LABEL" - value: usage: "LABEL" - description: usage: "LABEL"
В примере выше (блок backend_rest_ip ) содержится информация по порту, на который работает backend.
добавьте в файл pg_hba.conf запись для предоставления доступа из сети, в которой запускается docker-контейнер (в примере выше default-диапазон таких адресов - 172.28.0.0/16):
... host all all 172.28.0.0/16 md5 ...
перезагрузите PostgreSQL;
запустите сервис postgres-exporter:
docker-compose up -d
проверьте, что метрики появились на порту (в примере выше это порт 9187):
curl http://10.128.0.73:9187/metrics -s | grep backend_rest_ip
В ответ вы получите метрики:
# HELP backend_rest_ip_id id description is here # TYPE backend_rest_ip_id counter backend_rest_ip_id{description="backend rest api",key="base",name="backend_rest",server="10.128.0.73:5432",value="10.128.0.81:5666"} 5
В запросе выше делается упор на кастомную (пользовательскую) метрику. Если она собирается - собирается весь набор предоставляемых PostgreSQL метрик.
добавьте scrape-задачу в prometheus.yml и перезапустите сервис (команда на перезапуск выполняется из директории, содержащей файл docker-compose.yml с помощью которого запускался сервис prometheus):
vim <path_to_prometheus.conf_file> ... - job_name: postgresql scrape_interval: 5s static_configs: - targets: - - 10.128.0.73:9187 #<ip_with_running_postgres_exporter>:<postgres_exporter_port> relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance ... # перезагружаем службу docker-compose kill -s SIGHUP prometheus
добавьте изменённый дашборд изменённый дашборд через JSON-модель (ID оригинального дашборда 9628 ). Для этого:
Вернитесь в интерфейс Grafana. В меню слева выберите вкладку «Dashboards» (цифра 1 на рисунке ниже).
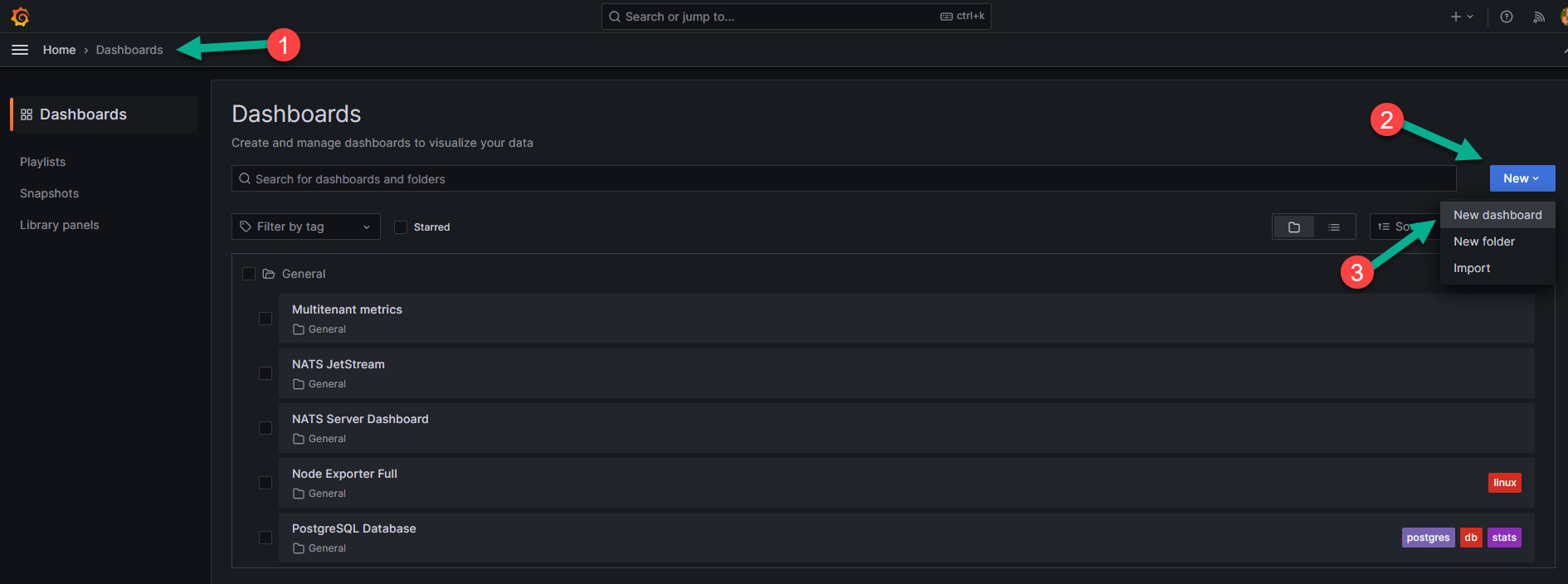
Нажмите на кнопку «New», обозначенную цифрой 2 на рисунке выше, и в выпадающем меню выберите опцию «New dashboard» («Новый дашборд»), указанную цифрой 3 на рисунке выше.
В поле, указанное стрелкой на рисунке ниже, загрузите скачанный по ссылке json-файл с изменённым дашбордом.
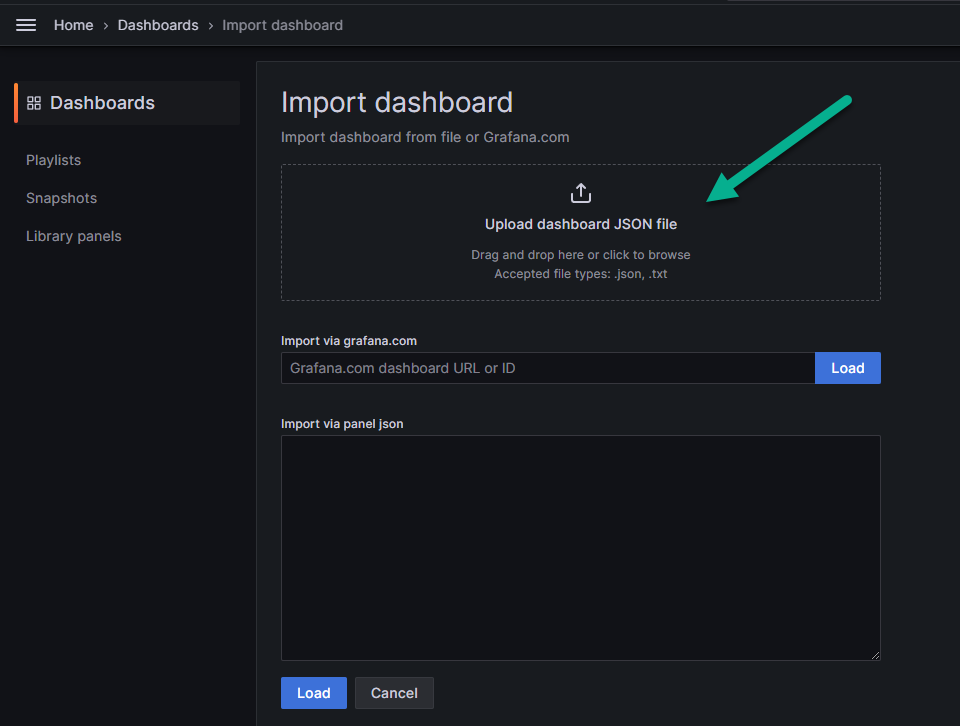
На появившейся странице заполните пустые поля:
name -название дашборда (цифра 1 на рисунке ниже);
folder - папку, в которой он будет отображаться (цифра 2 на рисунке ниже);
unique identifier - уникальный идентификационный номер дашборда (цифра 3 на рисунке ниже);
источник данных, в данном случае Prometheus (цифра 4 на рисунке ниже).
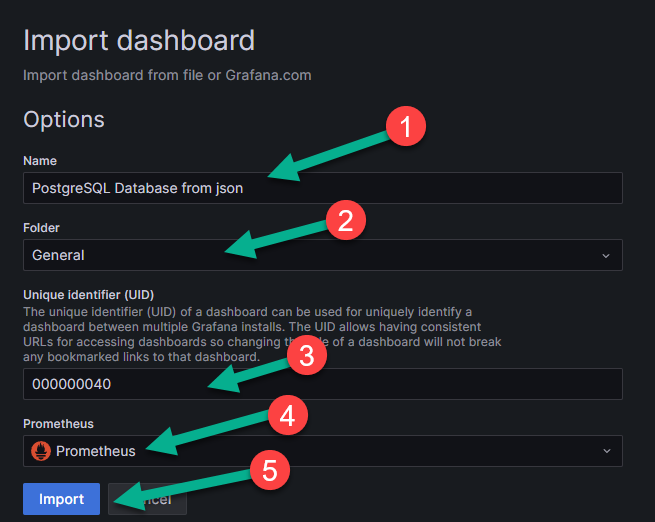
Сохраните дашборд, нажав на кнопку «Import» (цифра 5 на рисунке выше).
Примечание
У экспортированного дашборда в JSON-структуре могут быть UID-ы тестовой установки. При отсутствии данных или появлении ошибки необходимо заменить значение UID на актуальное.
Другим способом мониторинга PostgreSQL является подключения требуемой БД через Data Source в Grafana и выполнение запросов на сбор метрик напрямую через БД. В примере ниже будет создан пользователь Prometheus для подключения к БД (при необходимости имя роли можно изменить):
Создаём пользователя и выдаём нужные права:
# все команды выполняются после подключения к базе pma create role prometheus with password 'prometheus'; grant CONNECT on DATABASE pma to prometheus; GRANT SELECT ON ALL TABLES IN SCHEMA public TO prometheus; alter role prometheus with login; grant USAGE on SCHEMA monitoring TO prometheus; grant USAGE on SCHEMA pipelinedb TO prometheus; grant USAGE on SCHEMA sys TO prometheus; GRANT SELECT ON ALL TABLES IN SCHEMA monitoring TO prometheus; GRANT SELECT ON ALL TABLES IN SCHEMA pipelinedb TO prometheus; GRANT SELECT ON ALL TABLES IN SCHEMA sys TO prom?theus;
Подключаем PostgreSQL в качестве источника данных, для чего выполняем уже знакомую последовательность действий:
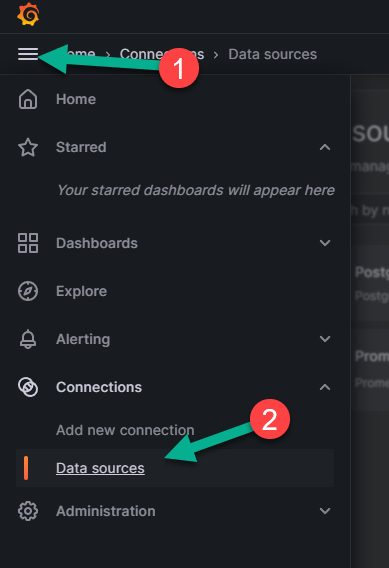
Заходим в меню слева (цифра 1 на рисунке ниже), где выбираем пункт «Data sources» (цифра 2 на рисунке ниже), который находится в блоке «Connections».
На появившейся странице из списка источников выбираем PostgreSQL (цифра 2 на рисунке ниже) и нажав на него.
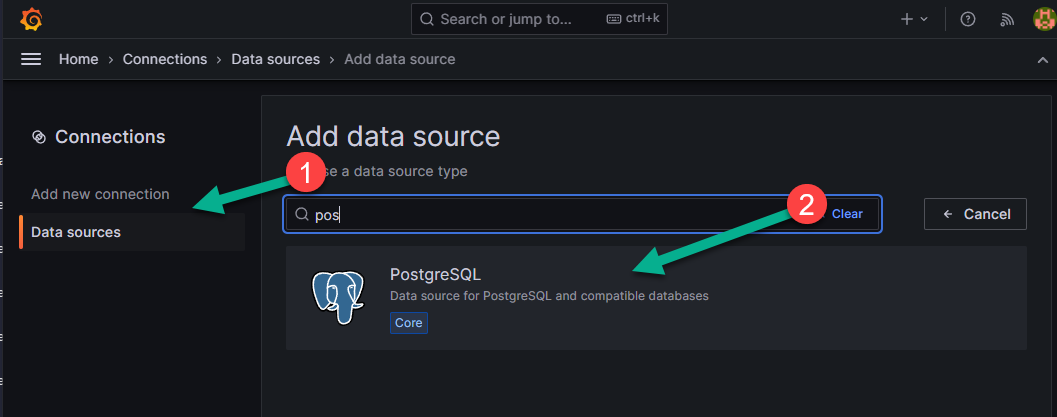
Заполняем нужные поля:
- PostgreSQL Connection - уажите параметры подключения PostgreSQL:
Name - название базы данных для подключения к ней в Grafana;
Host - IP-адрес вашей БД;
Database - фактическое название базы данных, под которым она определена на вашем сервере;
User - нужно выбрать пользователя, под которым вы будете подключаться к БД, а также password - пароль для подключения;
TSL/SSL mode - в выпавшем меню вы можете подключить или отключить режим проверки TSL/SSl, но для того, чтобы его подключить, вам нужен SSL-сертификат;
TSL/SSL method - можно выбрать метод обеспечения безопасного соединения между клиентом и сервером через интернет;
TSL/SSL Auth details - при использовании режима проверки TSL/SSL укажите данные аутентификации (сертификаты и ключи);
Connection limits - для большего уровня безопасности можно указать лимиты подключения:
Max open - ограничивает количество одновременно открытых соединений с базой данных. Это может быть важно для предотвращения перегрузки сервера и обеспечения стабильной работы.
Max idle - устанавливает максимальное время простоя для соединения, после которого оно будет закрыто. Это помогает освободить ресурсы сервера и предотвратить утечку соединений.
Max lifetime - определяет максимальную длительность соединения, после которого оно будет автоматически закрыто. Это может быть полезно для обеспечения безопасной и эффективной работы с базой данных.
- PostgreSQL details - укажите дополнительные детали о PostgreSQL:
Version - версию, которую вы используете;
TimescaleDB - вы можете подключить или отключить расширение для базы данных PostgreSQL, предназначенное для работы с временными рядами данных;
Min time interval - можно установить минимальный временной интервал, который рекомендуется устанавливать в соответствии с вашим циклом записи данных в БД.
Нажимаем на кнопку «Save and test» («Сохранить и проверить»), чтобы сохранить все настройки.
После того, как вы нажали на кнопку «Save and test», вам может высветиться ошибка, если вы некорректно заполнили какие-нибудь поля. Например ошибка о том, что такая база данных не существует, если вы неправильно заполнили поле о её фактическом названии.
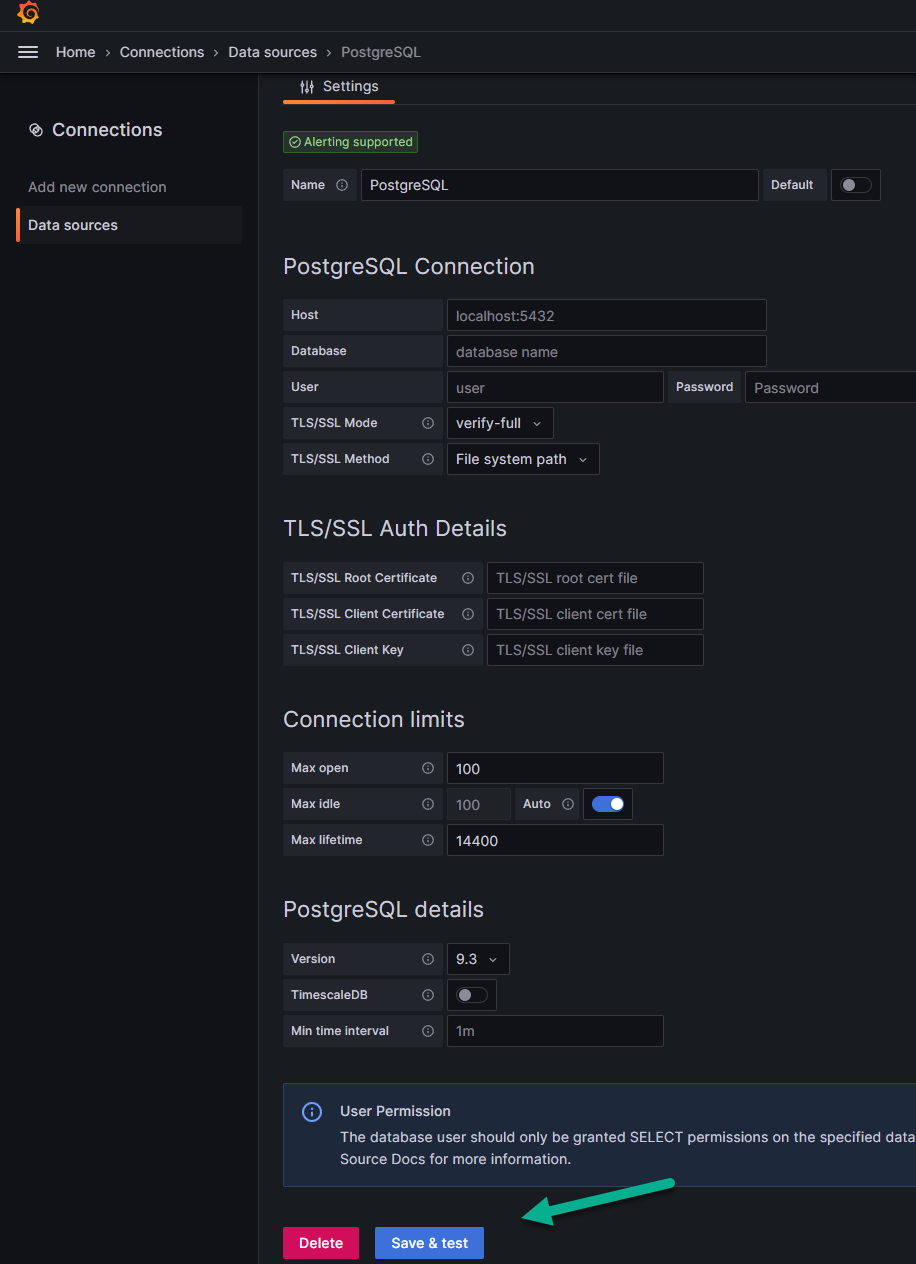
Если же вы всё верно заполнили то вам высветится сообщение «Database connection OK» об успешном подключении к базе данных, и на этом шаге подключение к БД будет завершено, после чего можно отправить запрос напрямую в неё, для чего:
В меню слева зайдите на страницу «Dashboards». Нажмите на кнопку «New», находящуюся справа (как в примере выше), и в выпадающем списке выберите «New dashboard».
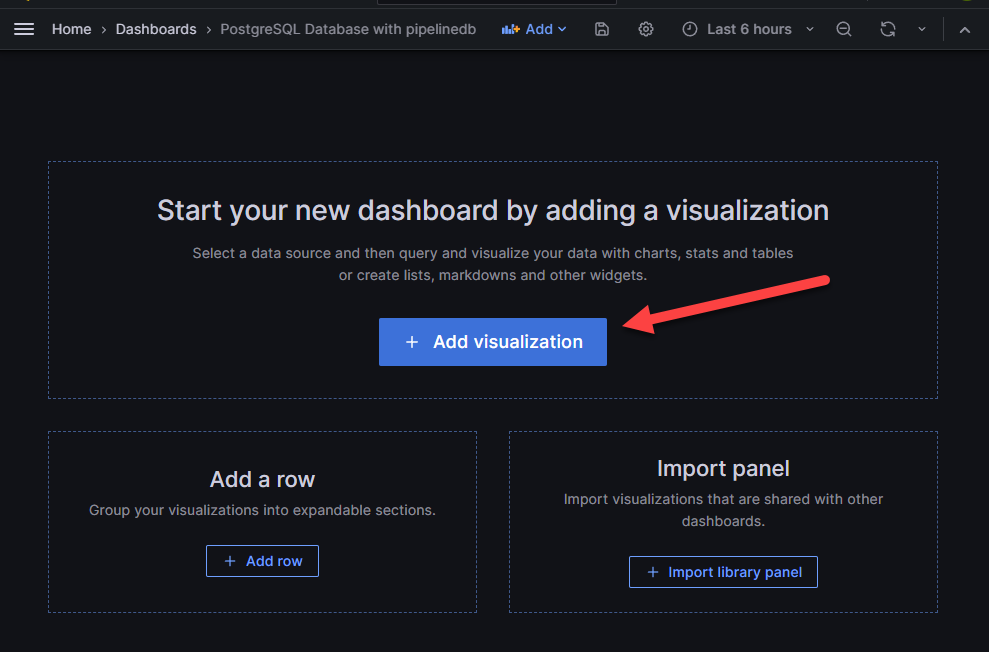
На появившейся странице выберите прямоугольник с опцией «Add visualization» («Добавить визуализацию»), показанную стрелкой на рисунке выше. Вы попадёте на следующую страницу:
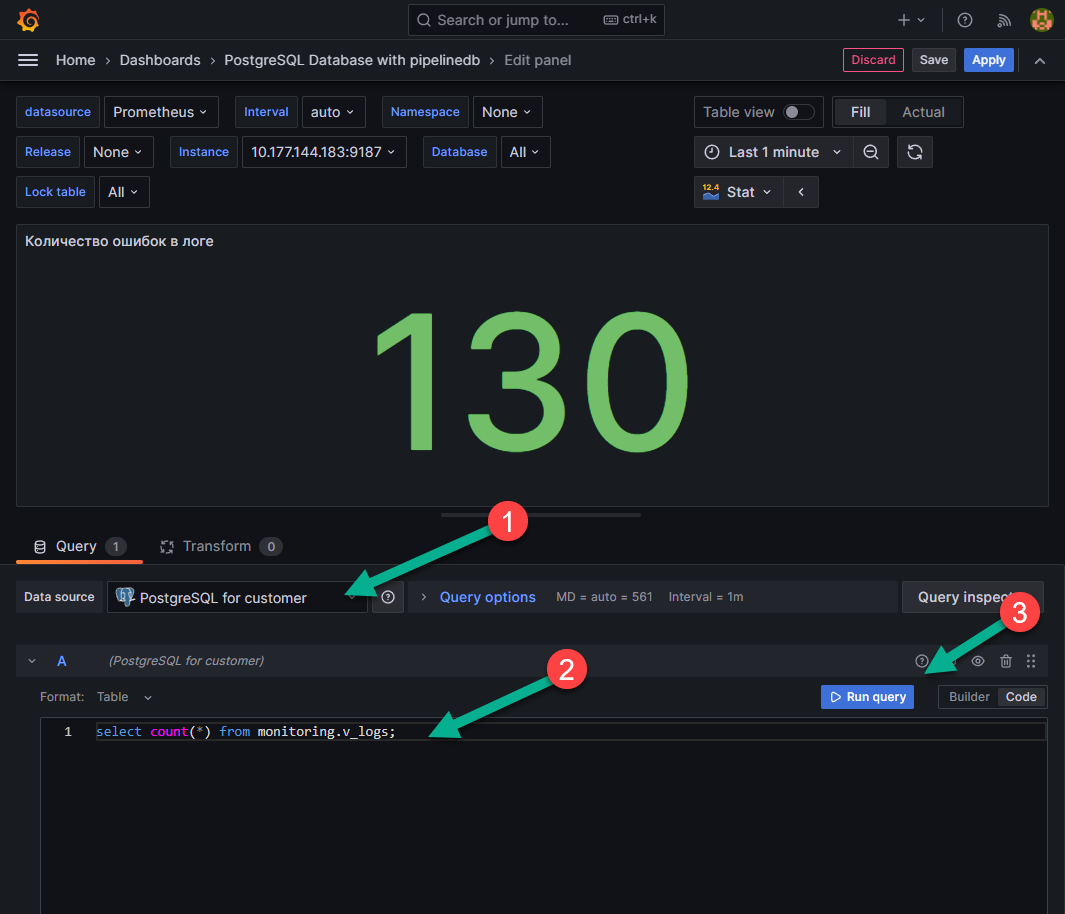
На появившейся странице в поле «Data source» («Источник данных») выбеерите «PostgreSQL for customer» (цифра 1 на рисунке выше).
В самом нижнем поле, указанном под цифрой 2 на рисунке выше, можно писать запросы к базе данных и запускать их с помощью кнопки «Run query» («Запустить запрос»), указанной цифрой 3 на рисунке выше.
Мониторинг PGBouncer
Для мониторинга используется exporter и дашборд для Grafana. Эта связка была выбрана, так как сразу поддерживает выбор сервера для мониторинга БД. Процесс настройки мониторинга следующий:
на узле, где есть необходимость проводить мониторинг PGBouncer, создаём файл docker-compose.yml и заполняем его:
version: '3.9' services: pgbouncer_exporter_spreaker: container_name: pgbouncer_exporter_spreaker image: spreaker/prometheus-pgbouncer-exporter ports: - "9127:9127" environment: PGBOUNCER_EXPORTER_HOST: 0.0.0.0 # IP, с которого будут приниматься подключения PGBOUNCER_EXPORTER_PORT: 9127 # порт, на котором будут доступны метрики PGBOUNCER_HOST: <pgbouncer_ip> # IP-адрес, на котором работает PGbouncer PGBOUNCER_PORT: <pgbouncer_port> # порт, на котором работает PGbouncer PGBOUNCER_USER: <username_with_access_to_pgbouncer_db> # пользователь, имеющий доступ в базу pgbouncer PGBOUNCER_PASS: <pass_from_user_with_access_to_pgbouncer_db> # пароль от пользователя, имеющего доступ в базу pgbouncer networks: - default networks: default: ipam: driver: default config: - subnet: 172.28.0.0/16
добавляем узел или всю подсеть, в которой запускается контейнер с экспортером (в примере выше default-диапазон таких IP-адресов - 172.28.0.0/16), в файл pg_hba.conf:
vim /etc/pgbouncer/pg_hba.conf ... host all all 172.28.0.0/16 md5 ...
перезагружаем службу PGbouncer;
проверяем, что под указанными данными пользователь может подключиться к БД pgbouncer:
psql -h <pgbouncer_ip> -p <pgbouncer_port> -U <username_with_access_to_pgbouncer_db> -d pgbouncer
При невозможности подключиться следует проверить наличие указанного пользователя (и md5-хэшированного пароля):
vim /etc/pgbouncer/userlist.txt ... "<username_with_access_to_pgbouncer_db>" "md5 hached <pass_from_user_with_access_to_pgbouncer_db>" ...
запускаем сервис pgbouncer_exporter_spreaker:
docker-compose up -d
проверяем наличие метрик (<pgbouncer_ip>:<pgbouncer_port>) с помощью команды:
curl <pgbouncer_ip>:<pgbouncer_port> -s
Полученный ответ будет содержать метрики:
# HELP python_gc_objects_collected_total Objects collected during gc # TYPE python_gc_objects_collected_total counter python_gc_objects_collected_total{generation="0"} 92.0 python_gc_objects_collected_total{generation="1"} 274.0 python_gc_objects_collected_total{generation="2"} 0.0 # HELP python_gc_objects_uncollectable_total Uncollectable object found during GC # TYPE python_gc_objects_uncollectable_total counter python_gc_objects_uncollectable_total{generation="0"} 0.0 python_gc_objects_uncollectable_total{generation="1"} 0.0 python_gc_objects_uncollectable_total{generation="2"} 0.0 # HELP python_gc_collections_total Number of times this generation was collected # TYPE python_gc_collections_total counter python_gc_collections_total{generation="0"} 55.0 python_gc_collections_total{generation="1"} 5.0 ...
добавляем scrape-задачу в prometheus.yml и перезапускаем сервис (команда на перезапуск выполняется из директории, содержащей файл docker-compose.yml, с помощью которого запускался сервис prometheus). Экспортер не поддерживает мультитаргетную настройку, поэтому для каждого узла pgboucner нужно создавать свой элемент job_name:
vim <path_to_prometheus.conf_file> ... - job_name: pgbouncer_spreaker scrape_interval: 5s static_configs: - targets: - <pgbouncer_ip>:<pgbouncer_port> relabel_configs: - source_labels: [ __address__ ] target_label: hostname regex: <pgbouncer_ip>:<pgbouncer_port> replacement: hostname_you_want_to_see_in_grafana_dashboard ... # перезагружаем службу docker-compose kill -s SIGHUP prometheus
добавляем в Grafana дашборд, как уже описывалось в примерах выше:
Во вкладке «Dashboards» (цифра 1 на рисунке ниже) нажмите на кнопку «New», обозначенную цифрой 2 на рисунке ниже, и в выпадающем меню выберите опцию «New dashboard» («Новый дашборд»), указанную цифрой 3 на рисунке ниже.
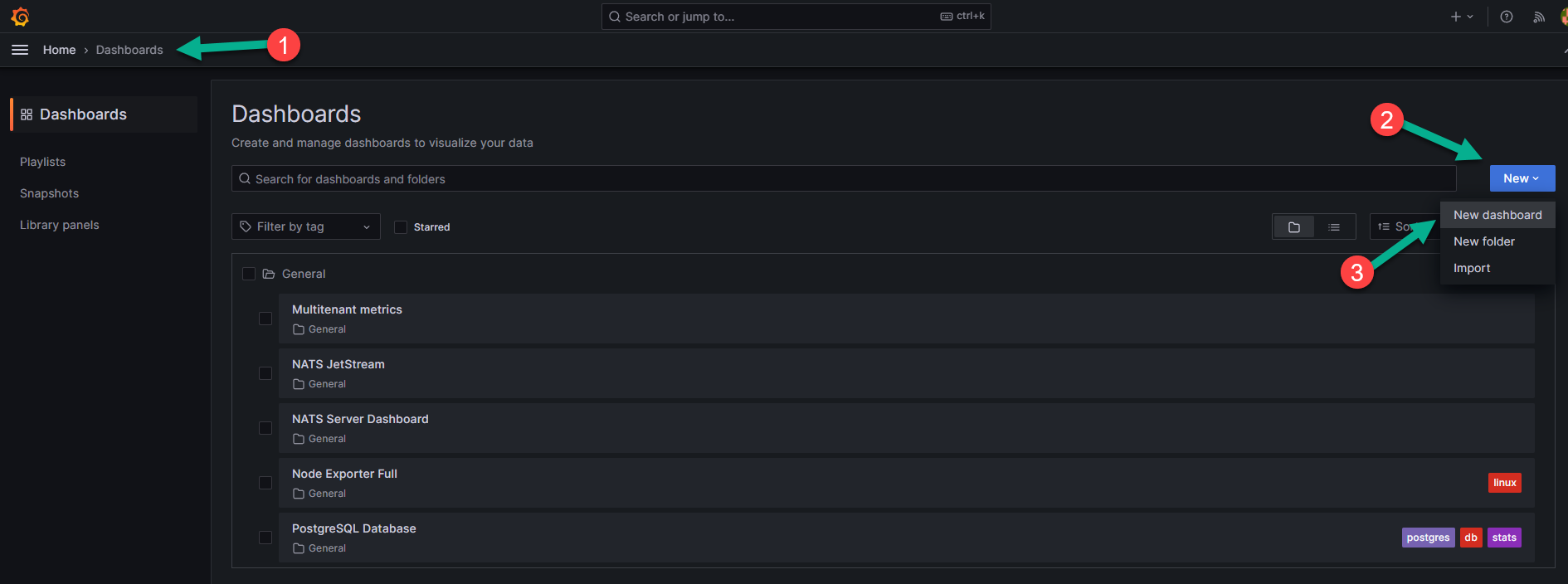
В поле, указанное стрелкой на рисунке ниже, загрузите скачанный по ссылке json-файл с изменённым дашбордом.
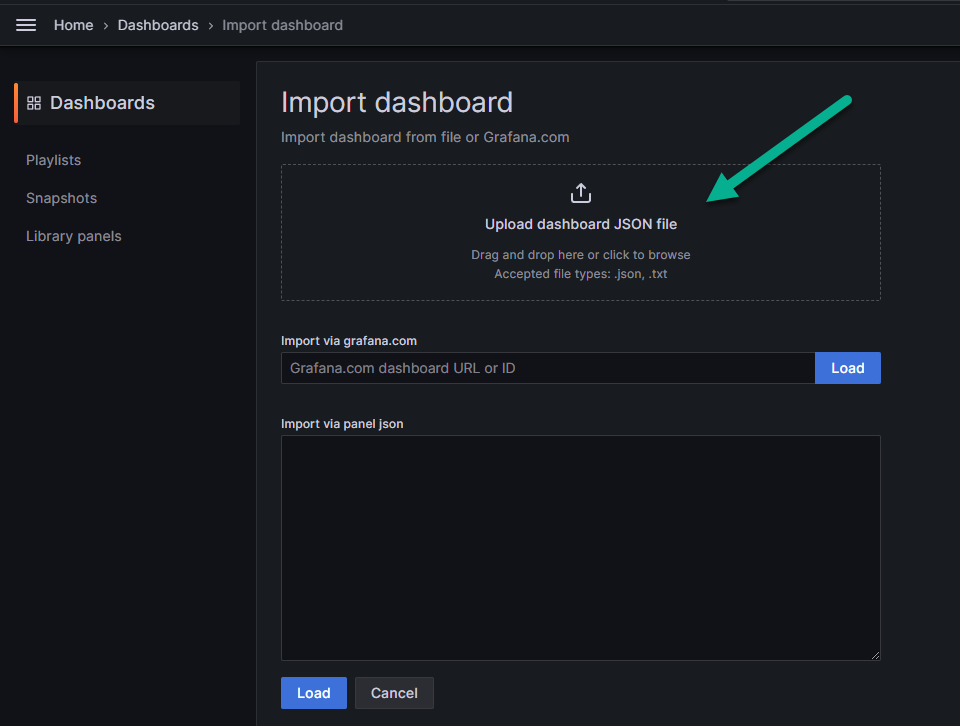
Заполните пустые поля на появившейся странице (цифры 1,2,3,4 на рисунке ниже) и нажмите на кнопку «Import» (цифра 5 на рисунке ниже).
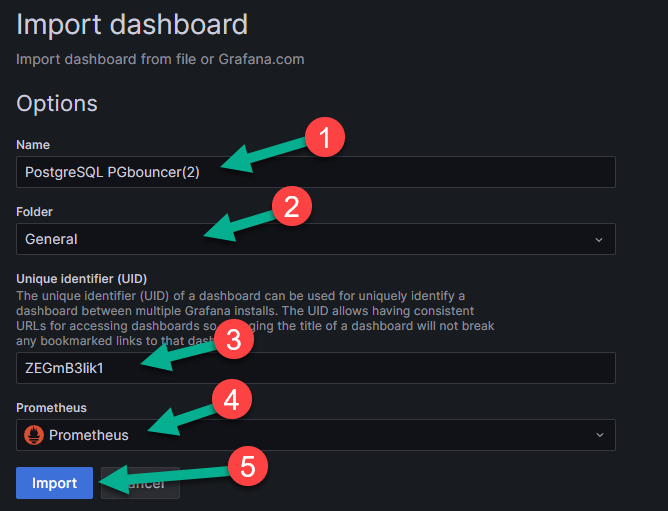
Примечание
у экспортированного дашборда в JSON-структуре могут быть UID-ы тестовой установки. При отсутствии данных или появлении ошибки необходимо заменить значение UID на актуальное.
Мониторинг NGINX
Базовая версия NGINX отдаёт очень мало параметров, которые можно отслеживать. Были проверены различные модули, расширяющие функционал логирования (в т.ч. через Telegraf), но результаты использования не соответствовали ожиданиям, поэтому было решено остановится на базовом функционале мониторинга. В конфигурации ниже будут использованы номера портов. Это не рекомендованные значения, а лишь те, на которых данная инсталляция была проверена и работает. При использовании других портов изменяйте их в соответствующих файлах. Для настройки мониторинга выполните следующие действия:
в конфигурационный файл NGINX добавьте модуль stub_status, который будет отдавать метрики:
server { listen 9999; location /metrics { stub_status; access_log off; allow 127.0.0.1; allow 172.28.0.0/16; #deny all; } }
Модуль stub_status можно добавлять в любой conf-файл, который считывается NGINX-ом и добавлен через директиву include в /etc/nginx/nginx.conf.
после добавления модуля проверьте синтаксис nginx и перезапустите службу:
sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful # если ошибок не выявлено - перезапускаем службу sudo systemctl restart nginx
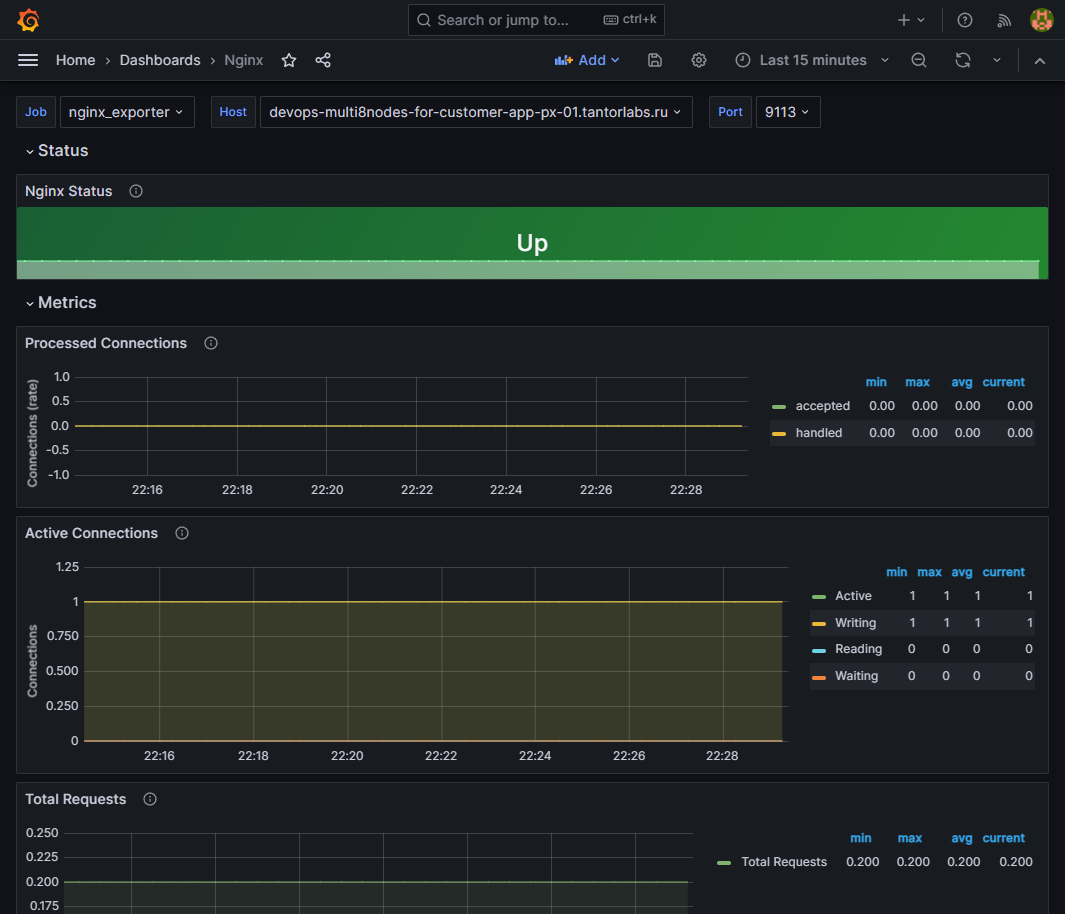
После проделанных операций NGINX будет отдавать метрики по пути http://<nginx_host_ip>:9999/metrics.
на узле, где нужно осуществлять мониторинг и установлен NGINX, создайте директорию prometheus и в ней файл docker-compose.yml:
--- version: "3.9" services: nginx_exporter: container_name: nginx_exporter image: nginx/nginx-prometheus-exporter ports: - "9113:9113" command: -nginx.scrape-uri=http://<nginx_host_ip>:9999/metrics networks: - default networks: default: ipam: driver: default config: - subnet: 172.28.0.0/16
запустите сервисы из docker-compose.yml файла:
docker-compose up -d
проверьте статус контейнера и его логи:
docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e8f9d6345b58 nginx/nginx-prometheus-exporter "/usr/bin/nginx-prom…" 4 hours ago Up 4 hours 0.0.0.0:9113->9113/tcp, :::9113->9113/tcp nginx_exporter docker logs nginx_exporter NGINX Prometheus Exporter version=0.11.0 commit=e4a6810d4f0b776f7fde37fea1d84e4c7284b72a date=2022-09-07T21:09:51Z, dirty=false, arch=linux/amd64, go=go1.19 2023/11/13 15:01:46 Starting... 2023/11/13 15:01:46 Listening on :9113 2023/11/13 15:01:46 NGINX Prometheus Exporter has successfully started
проверьте доступность метрик на порту 9113:
curl http://10.177.144.185:9113/metrics -s # HELP nginx_connections_accepted Accepted client connections # TYPE nginx_connections_accepted counter nginx_connections_accepted 5 # HELP nginx_connections_active Active client connections # TYPE nginx_connections_active gauge nginx_connections_active 1 # HELP nginx_connections_handled Handled client connections # TYPE nginx_connections_handled counter nginx_connections_handled 5 # HELP nginx_connections_reading Connections where NGINX is reading the request header # TYPE nginx_connections_reading gauge nginx_connections_reading 0 # HELP nginx_connections_waiting Idle client connections # TYPE nginx_connections_waiting gauge nginx_connections_waiting 0 # HELP nginx_connections_writing Connections where NGINX is writing the response back to the client # TYPE nginx_connections_writing gauge nginx_connections_writing 1 # HELP nginx_http_requests_total Total http requests # TYPE nginx_http_requests_total counter nginx_http_requests_total 3173 # HELP nginx_up Status of the last metric scrape # TYPE nginx_up gauge nginx_up 1 # HELP nginxexporter_build_info Exporter build information # TYPE nginxexporter_build_info gauge nginxexporter_build_info{arch="linux/amd64",commit="e4a6810d4f0b776f7fde37fea1d84e4c7284b72a",date="2022-09-07T21:09:51Z",dirty="false",go="go1.19",version="0.11.0"} 1
добавьте job в prometheus.yml:
... - job_name: nginx_exporter scrape_interval: 5s static_configs: - targets: - <nginx_host_ip>:9113 ...
добавьте дашборд в Grafana (инструкция по добавлению описана выше - ссылка);
проверьте наличие метрик в добавленном дашборде: