Профилировщик запросов (Query Profiler)
Порядок установки модулей, расширений см. в разделе Установка дополнительных элементов.
Модуль Query Profiler предназначен для профилирования запросов. Работа данного модуля основана на сборе статистики из расширения pg_stat_statements. Все данные из pg_stat_statements группируются особым образом, чтобы исключить дублирование для идентичных запросов.
Попасть на эту страницу можно, нажав на «Профилировщик запросов» в левой панели меню экземпляра.
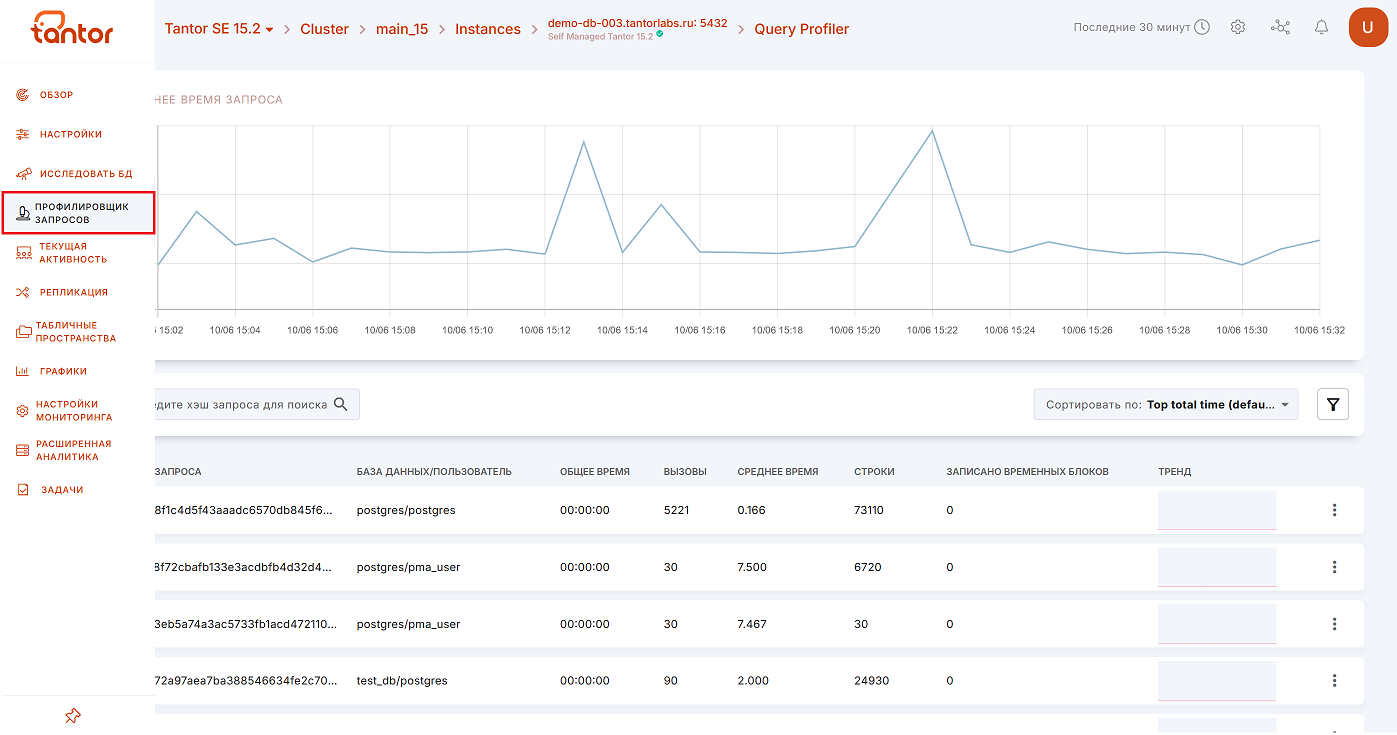
На каждой итерации сбора статистической информации делается выборка только 50 самых длительных запросов, все остальные группируются в блок other. Рассмотрим функционал модуля, согласно нумерации, обозначенной на рисунке ниже:
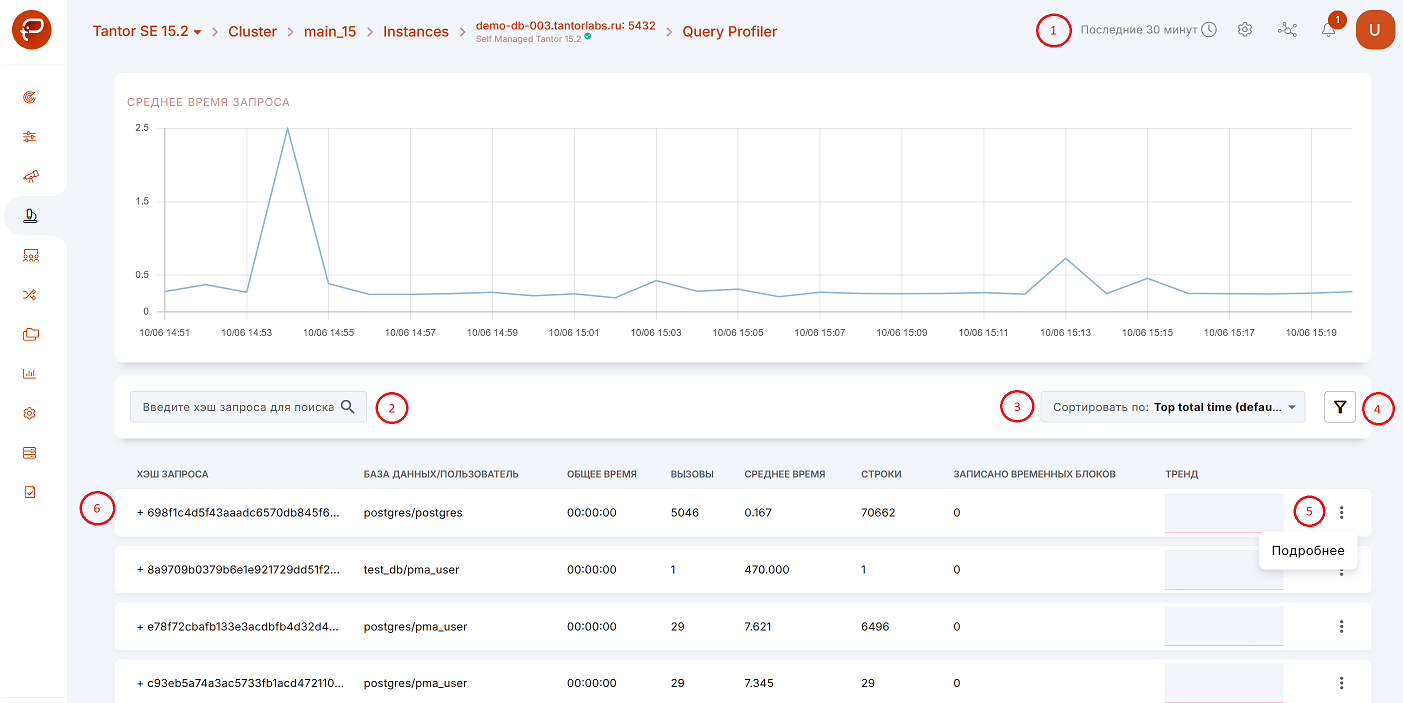
График (цифра 1 на рисунке выше) отображает среднее время выполнения запросов. Выпадающий список в правом верхнем углу дает возможность выбрать временной интервал, за который необходимо показать информацию. Выбранный интервал времени, кроме того, влияет на список запросов ниже. Временной интервал имеет семь вариантов на выбор:
последние 30 минут (по умолчанию),
последний час,
последние 3 часа,
последние 8 часов,
последние 12 часов,
последний день,
последние 7 дней.
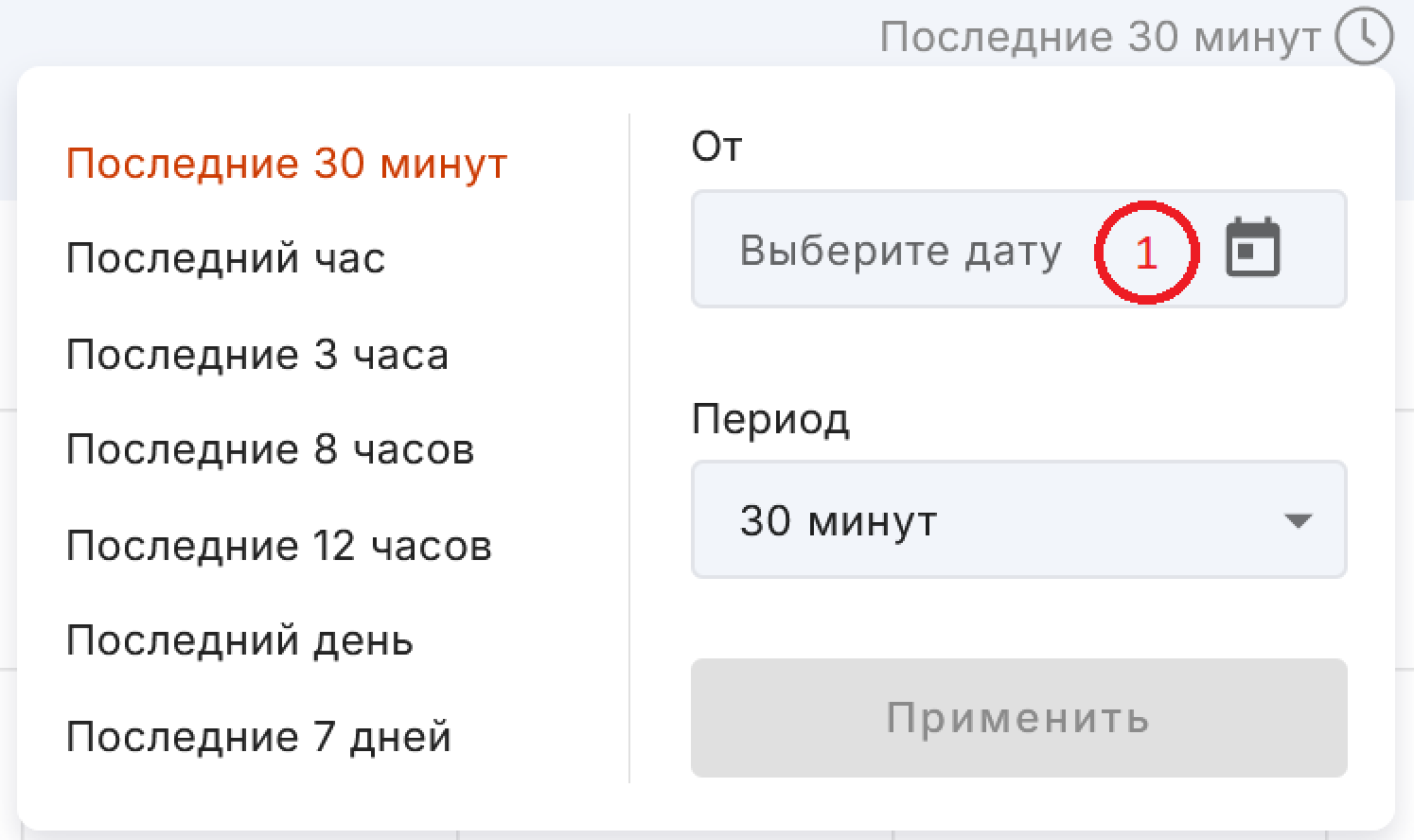
Также можно выбирать дату, от которой будет отсчитан интересующий интервал (цифра 1 на рисунке выше).
Поиск по хэшу запроса (цифра 2 одним рисунком выше).
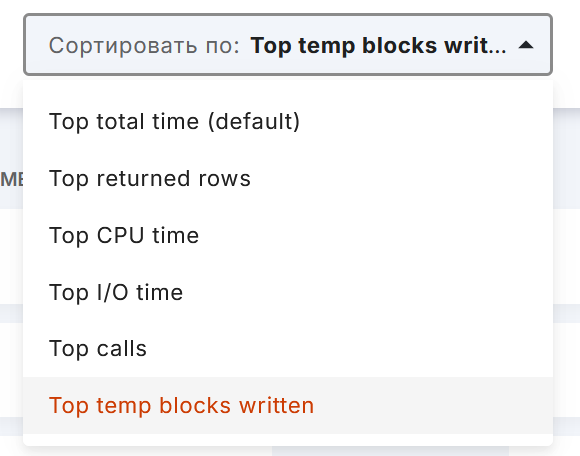
Сортировка запросов (цифра 3 одним рисунком выше):
Top total time (default) - общее время (по умолчанию);
Top returned rows - количество возвращенных строк;
Top CPU Time - время ЦП;
Top IO Time - время ввода-вывода;
Top calls - количество вызовов;
Top temp blocks written - количество блоков, записанных во временном хранилище.
Фильтр, позволяющий выполнить фильтрацию по базам данных (цифра 4 двумя рисунками выше).
Меню с опцией «Подробнее» для более детального рассмотрения запроса (цифра 5 двумя рисунками выше).
Символ «+»- открывает подстроку(рисунок ниже) для того, чтобы увидеть сам запрос (цифра 6 двумя рисунками выше).

Скопировать запрос в буфер (цифра 1 на рисунке выше).
Для просмотра более детальной информации по запросу необходимо кликнуть на строку или выбрать в контекстном меню «Подробнее»:
Вкладка «Статистика»
При переходе к более детальной информации по запросу в первую очередь откроется вкладка «Статистика».
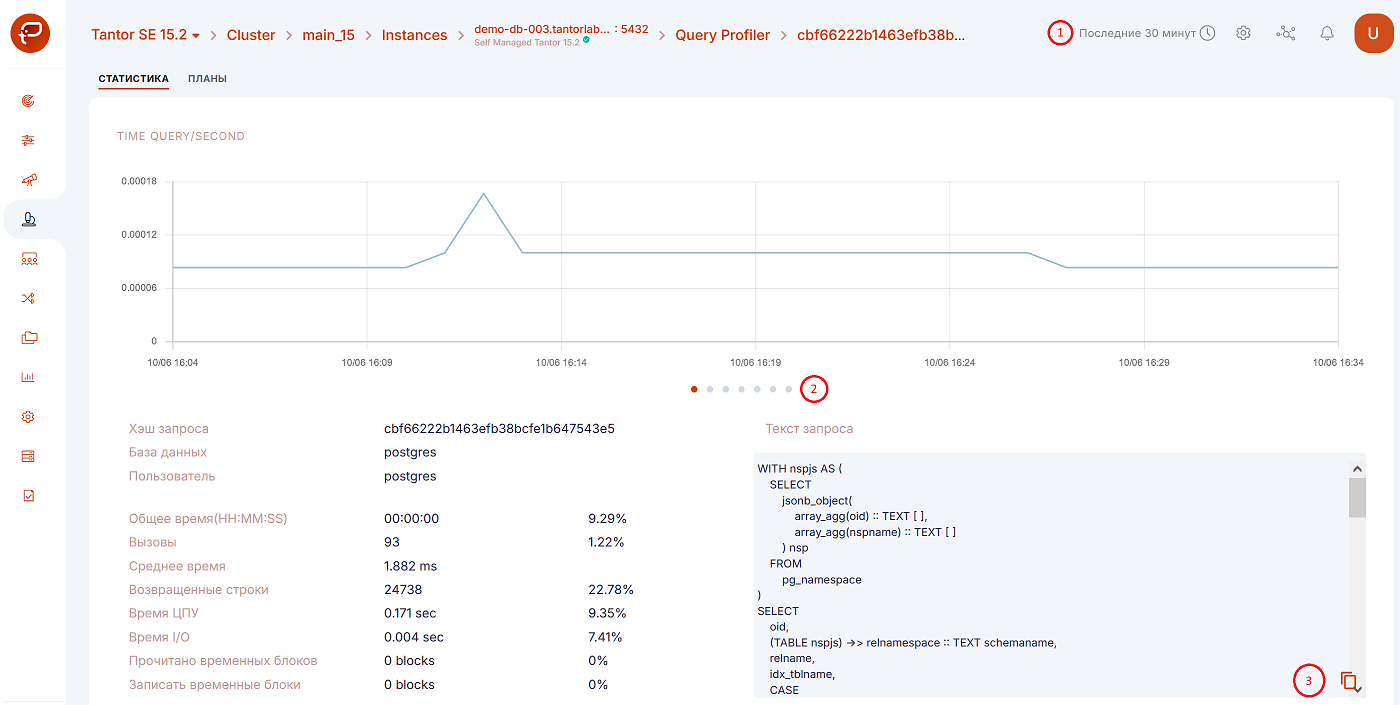
Рассмотрим приведенную выше страницу в соответствии с предоставленной нумерацией:
График имеет возможность отображать данные за определенный временной интервал (цифра 1 на рисунке выше). Вы можете выбрать один из семи вариантов временного интервала:
последние 30 минут (по умолчанию),
последний час,
последние 3 часа,
последние 8 часов,
последние 12 часов,
последний день,
последняя неделя.
Также можно выбирать дату, от которой будет отсчитан интересующий интервал (цифра 1 на рисунке выше).
Для вашего удобства есть шесть различных графиков. Вы можете переключаться между ними, нажимая на точки (цифра 2 одним рисунком выше выше):
Time Query/Second
Calls/Second
Rows/Second
CPU Time/ Second
IO Time/Second
Dirtied Blocks/Second
Temp Blocks(Write)/Second
Скопировать запрос в буфер (цифра 3 одним рисунком выше).
Вкладка «Планы»
Для работы с планами запросов, необходимо установить расширение pg_store_plans (см. подпункт Установка и настройка расширения pg_store_plans).
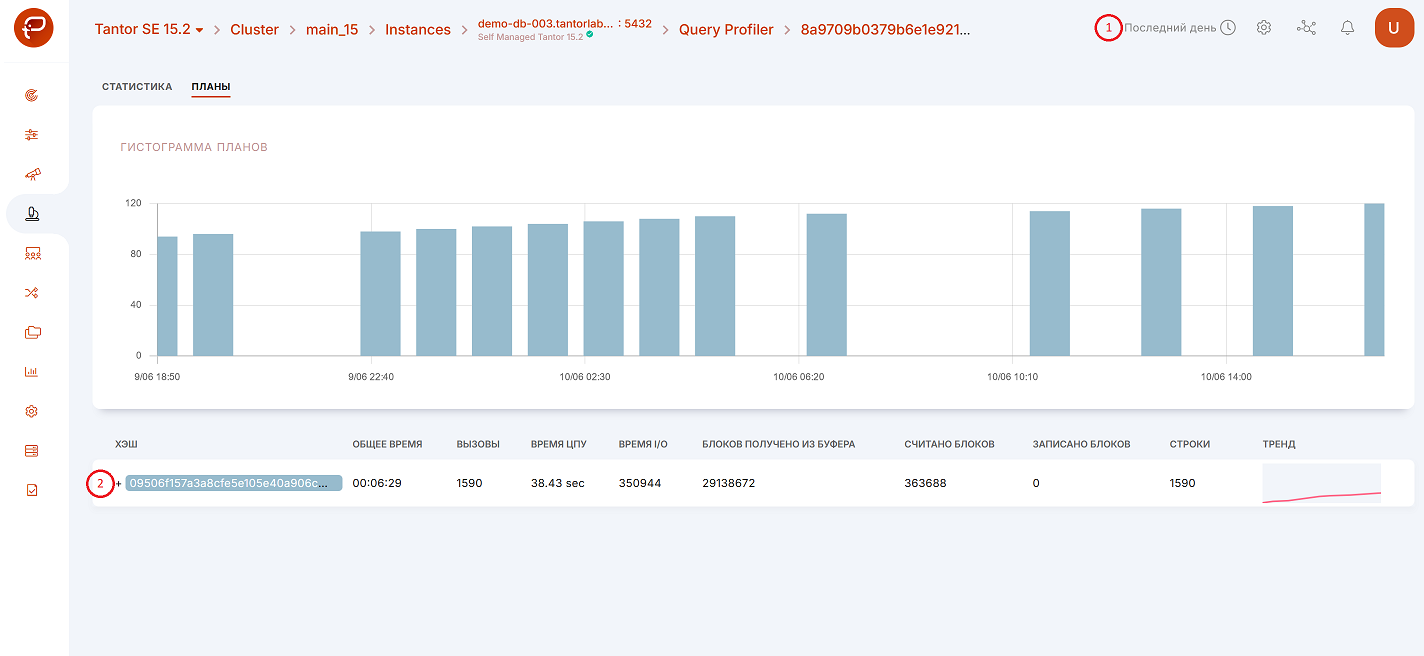
Данные об использовании планов запросов представлены в формате гистограмм. Каждый план отображается уникальным цветом. Высота столбца в гистограмме по каждому из планов зависит от количества вызовов данного плана.
Рассмотрим приведенный выше скриншот в соответствии с предоставленной нумерацией. Вы можете выбрать один из семи вариантов временного интервала (цифра 1 на рисунке выше):
последние 30 минут (по умолчанию),
последний час,
последние 3 часа,
последние 8 часов,
последние 12 часов,
последний день,
последняя неделя.
Также можно выбирать дату, от которой будет отсчитан интересующий интервал (цифра 1 на рисунке выше).
При нажатии на символ «+» (цифра 2 одним рисунком выше) вы можете увидеть план выполнения, используемый для выбранного запроса.
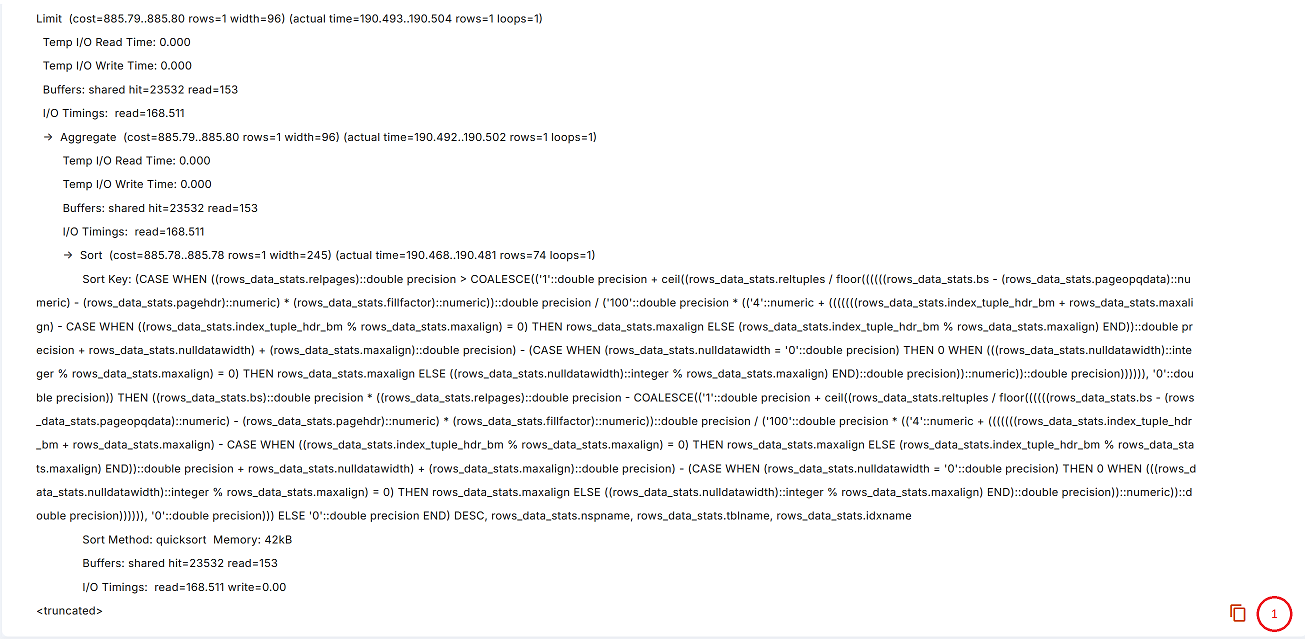
Скопировать план выполнения в буфер (цифра 1 на рисунке выше).
Анализатор планов запросов
Анализатор планов запросов интегрирован в платформу Tantor на основе сервиса https://explain.tensor.ru. Данная интеграция позволяет пользователю проводить анализ запросов и логов базы данных в рамках платформы Tantor и не требует отправки запросов и данных, находящихся в них во внешние сервисы. Более того, платформа Tantor собирает и хранит запросы в соответствии с установленной конфигурацией, существенно облегчая поиск запросов по таким параметрам, как время запроса, количество строк и многое другое.
Конфигурация
Для корректной работы необходимо установить следующие расширения:
pg_stat_statements, который поставляется в каталоге contrib дистрибутива PostgreSQL и Tantor DB всех версий;
pg_store_plans сборки Tantor (отличается от находящегося в общем доступе).
Методы доступа
Существует три метода доступа к анализатору планов запросов.
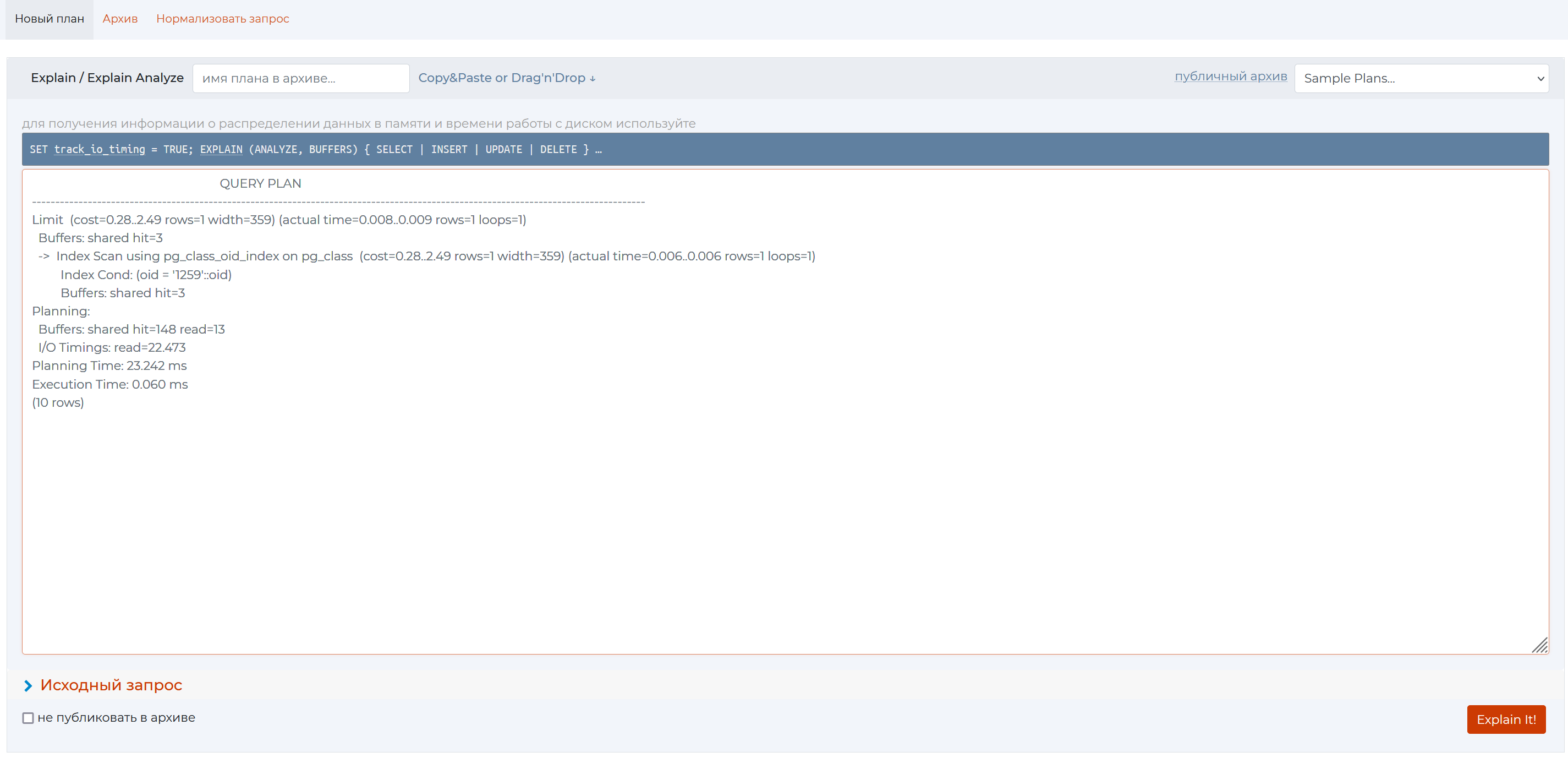
Метод 1: Доступ из верхнего меню:

При нажатии на доступ из верхнего меню расширение откроется в новой вкладке и не будет содержать запросов, находящихся в платформе. Этот функционал позволяет скопировать в новое окно любой запрос для проведения анализа:
Метод 2: Доступ из экрана «Overview» («Обзор») экземпляра через запрос «5 самых длительных запросов».
Данный метод позволяет проанализировать запрос, который попал в TOP 5, для доступа следует:
нажать внизу плашки «5 самых длительных запросов» на текст интересующего запроса. Откроется меню;
в открывшемся меню нажать на опцию «Подробнее»:
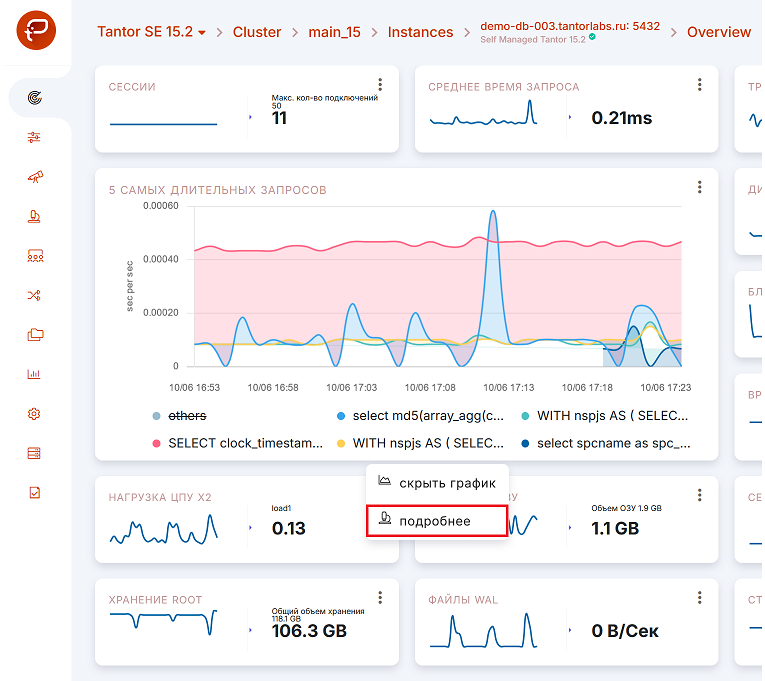
Откроется окно;
в открывшемся меню нажать на «Планы»:
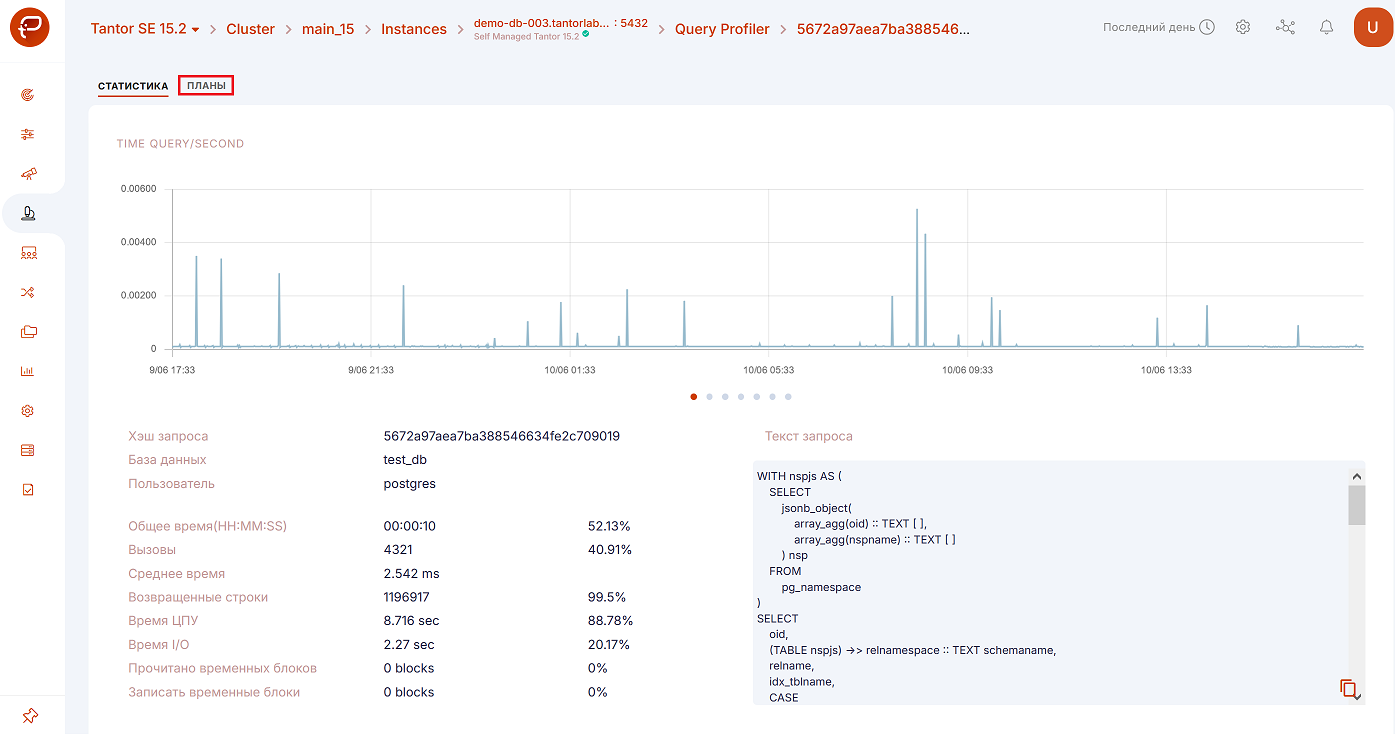
В результате откроется окно с анализом:
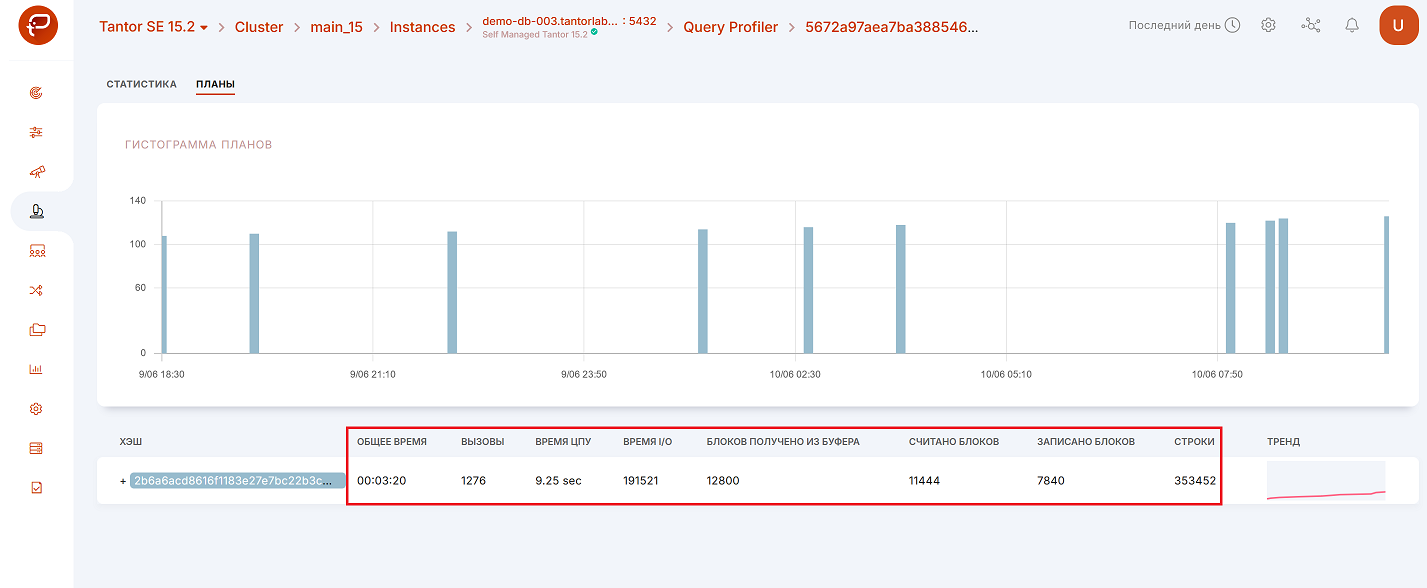
Метод 3: Доступ через экран Queries.
Данный метод позволяет проанализировать запрос, который попал в Top 50 запросов, которые собирает и анализирует платформа. Для доступа следует:
нажать на «Профилировщик запросов»:
нажать на интересующий запрос:
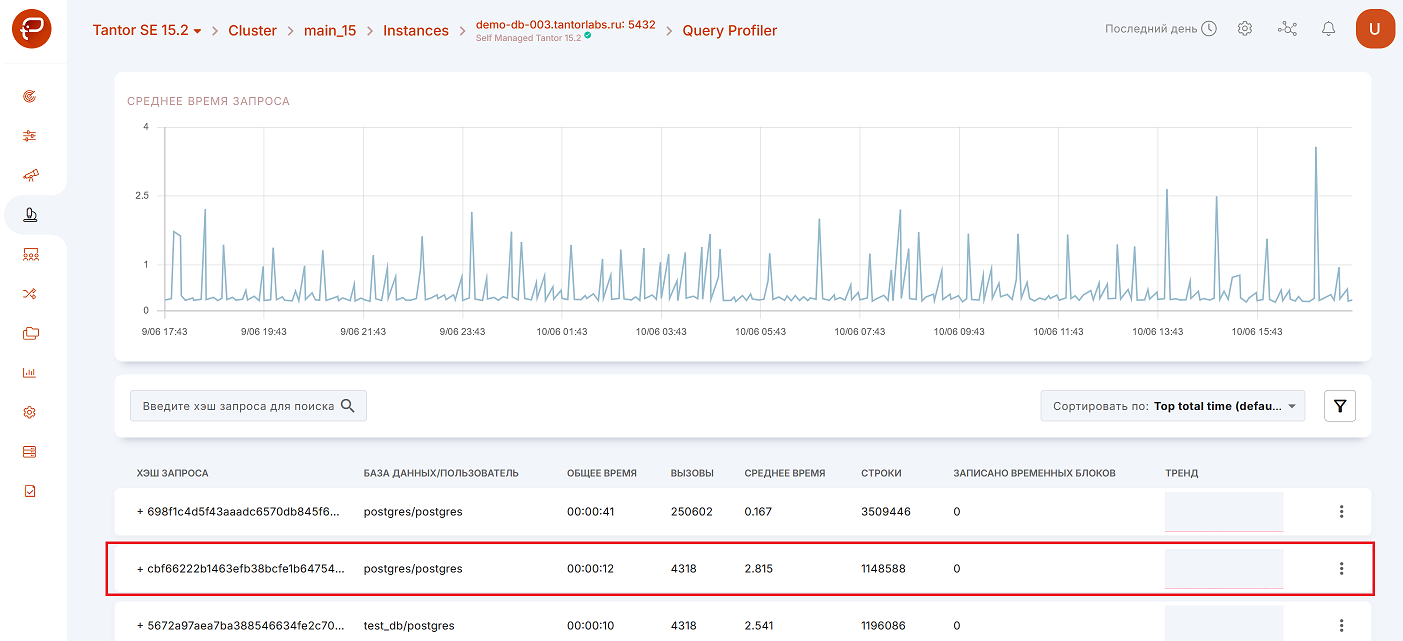
Высветится страница со статистикой по запросу:
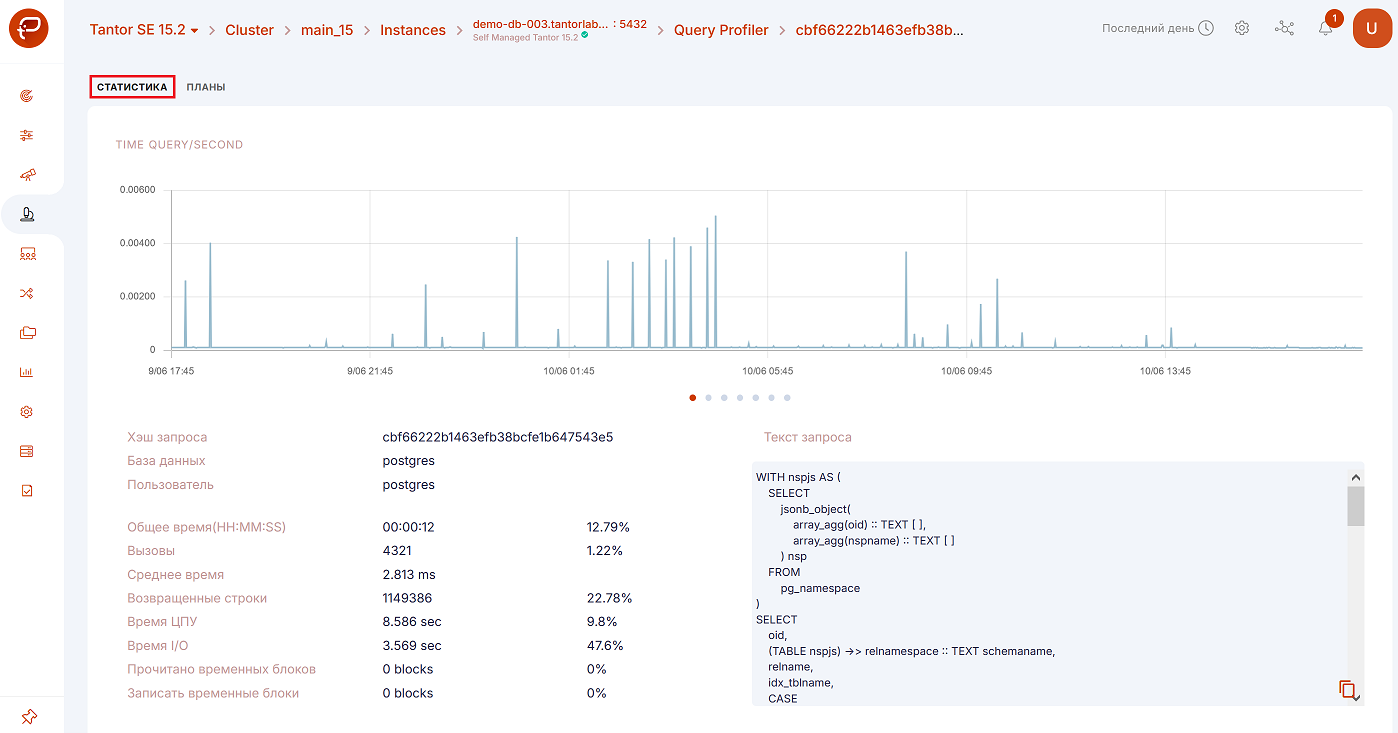
на открывшейся странице перейти во вкладку «Планы», обозначенную цифрой 1 на рисунке ниже:
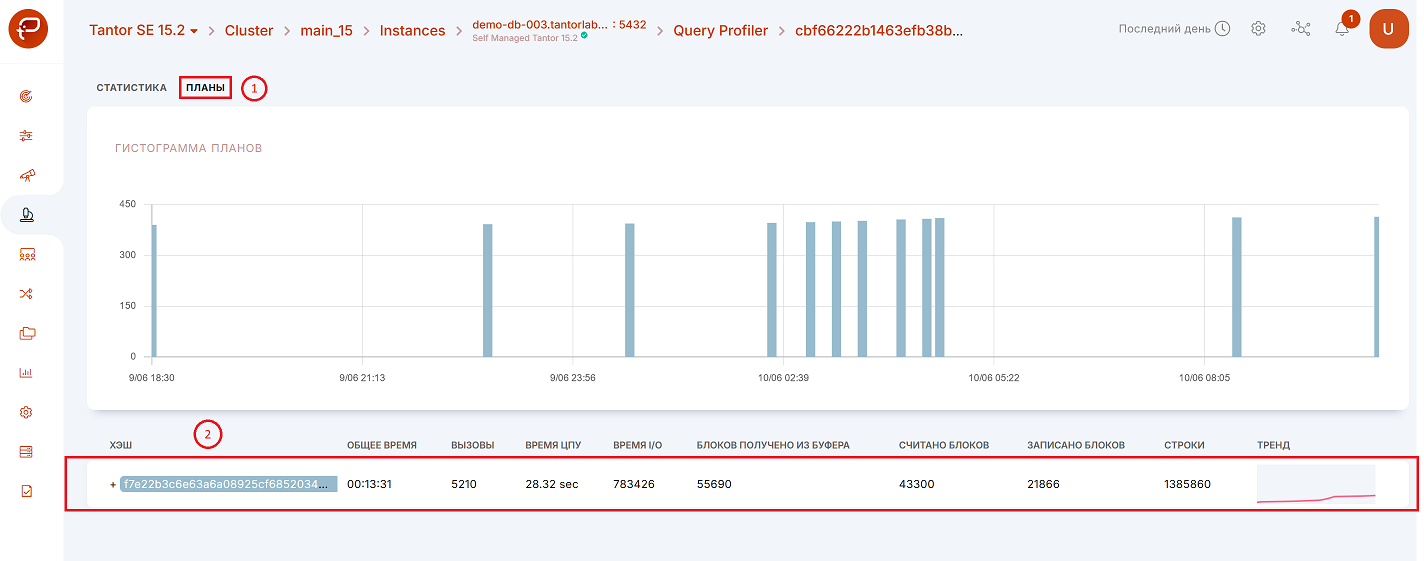
Откроется страница с разными планами запроса. Нажмите на интересующий вас план (цифра 2 на рисунке выше) и попадёте на страницу с анализом данного плана:
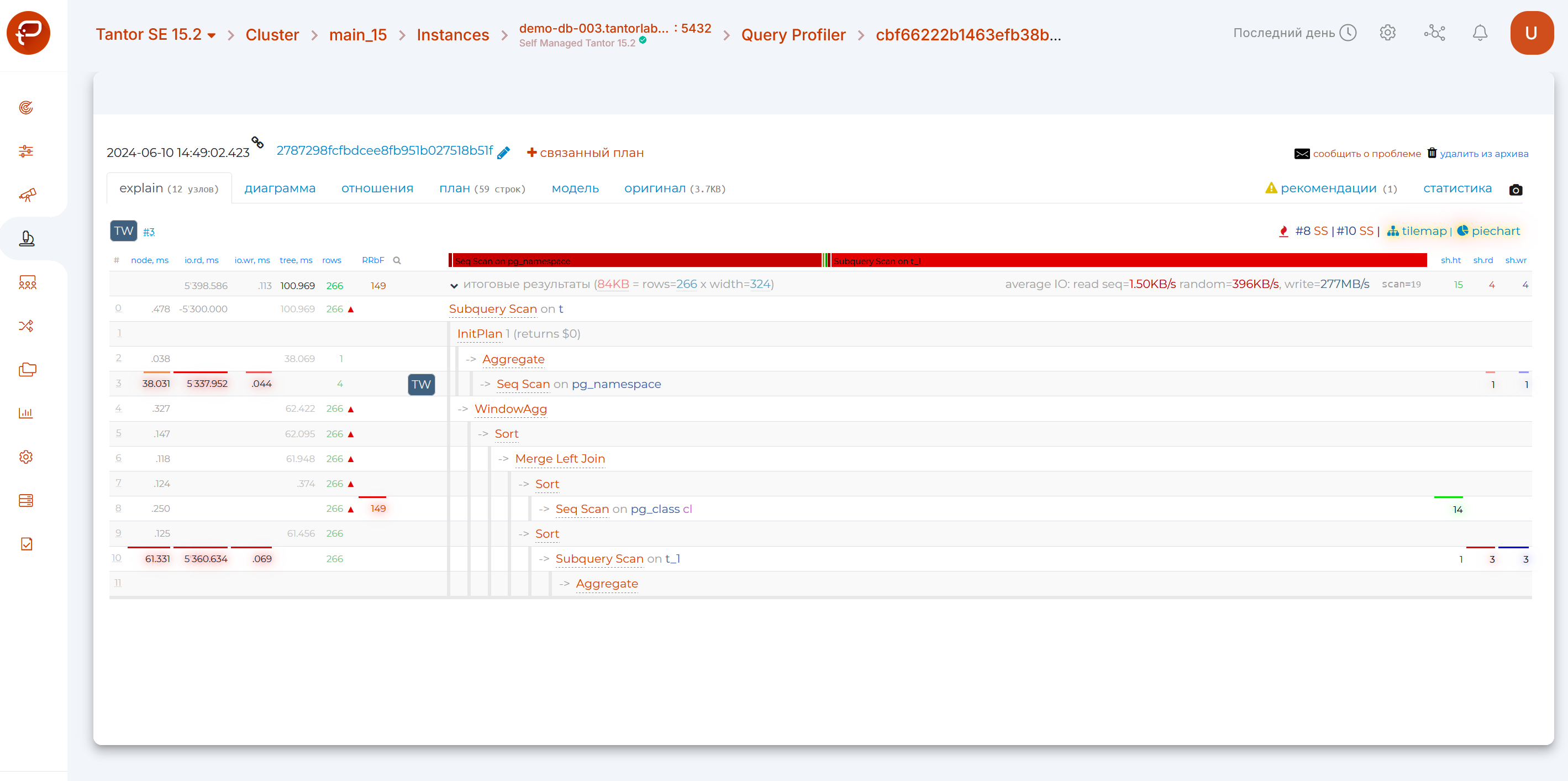
Основные компоненты
Навигатор [1]
Позволяет оценить с помощью полоски-навигатора, сколько времени занял каждый узел. При нажатии на него произойдет переход на нужный узел:
Если доминируют красные сегменты - вы тратите много времени на чтение данных (Seq Scan, Index Scan, Bitmap Heap Scan, …), если желтые - на их обработку (Aggregate, Unique, …), а зеленых Join должно быть не слишком много.
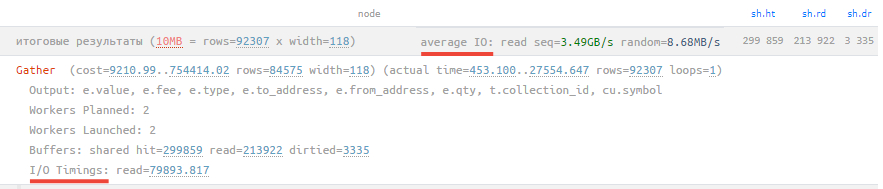
Average IO [1]
Если в вашем плане присутствуют показатели времени, затраченного на операции ввода-вывода (атрибут I/O Timings при включенном параметре track_io_timing), то теперь в строке итогов можно мгновенно оценить усредненные показатели скорости доступа к диску при последовательном и случайном чтении или записи:
Предупреждение
Если вы видите тут цифры в единицы MB/s, хотя база находится на SSD, то где-то в работе дисковой подсистемы явно есть проблема.
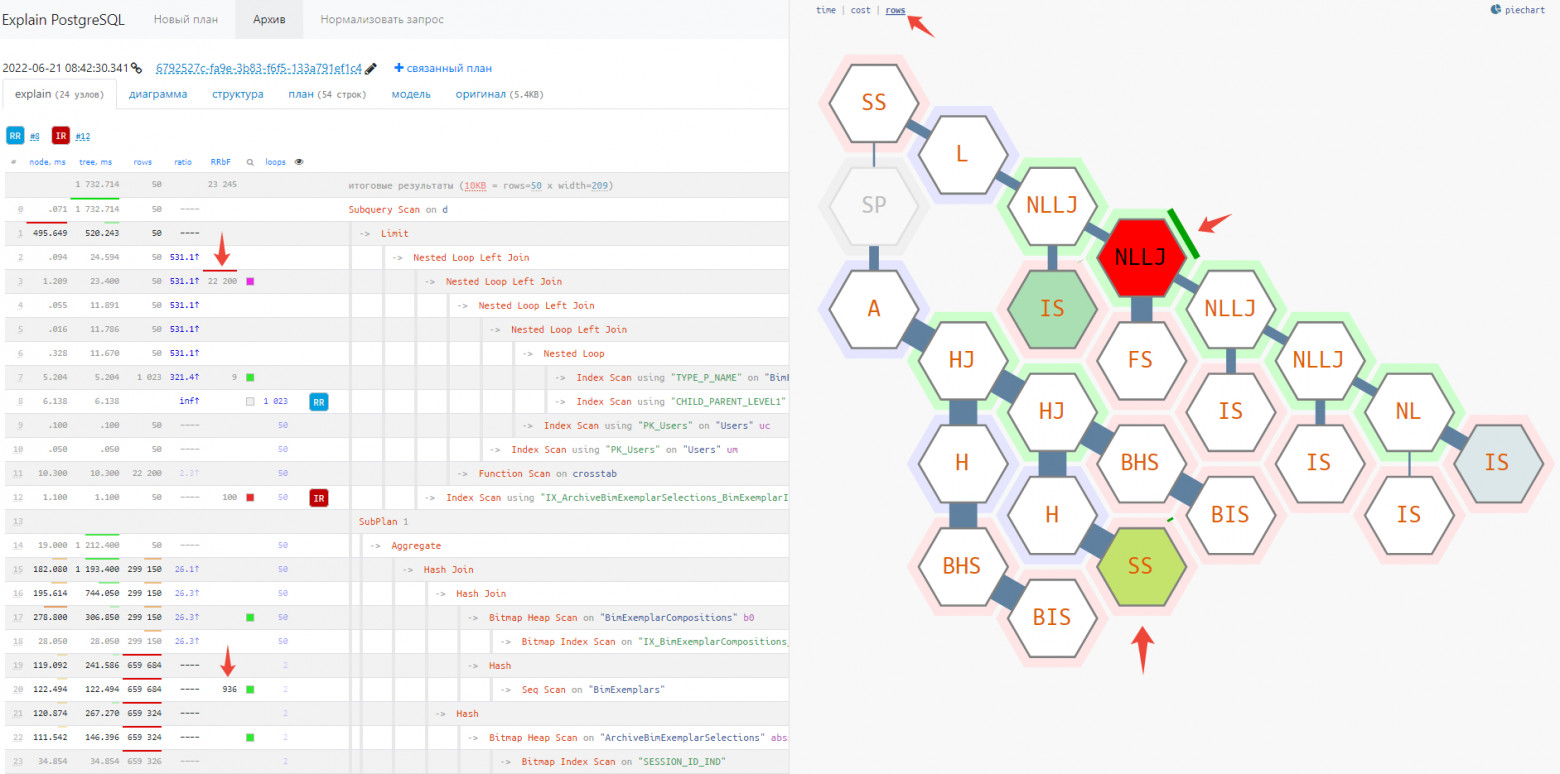
Дерево rows/RRbF [1]
На tilemap-диаграмме плана режим rows - в нем вы можете мгновенно оценить, в каком сегменте плана генерируется или фильтруется чересчур много записей.
В этом режиме подсвечиваются те узлы, на которых было отброшено из-за несоответствия условию (Rows Removed by …) наибольшее количество записей, а «ширина» связи пропорциональна количеству записей, которые были переданы вверх по дереву.
Чем ярче узел и толще его «ветви», тем более пристально стоит к нему присмотреться:
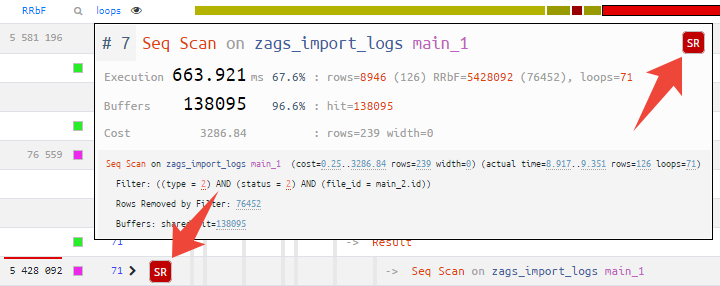
Тултип узла [1] [2]
Наводя курсор на узел в навигаторе или любой другой диаграмме, вы сразу видите все иконки рекомендаций, которые советует наш сервис:

Если это подсказка об индексе, то простого клика по ней достаточно, чтобы перейти к предлагаемым вариантам подходящих индексов.
Также для всех больших чисел в тексте узла добавлены разделители разрядов, чтобы сходу воспринимать порядок величин.
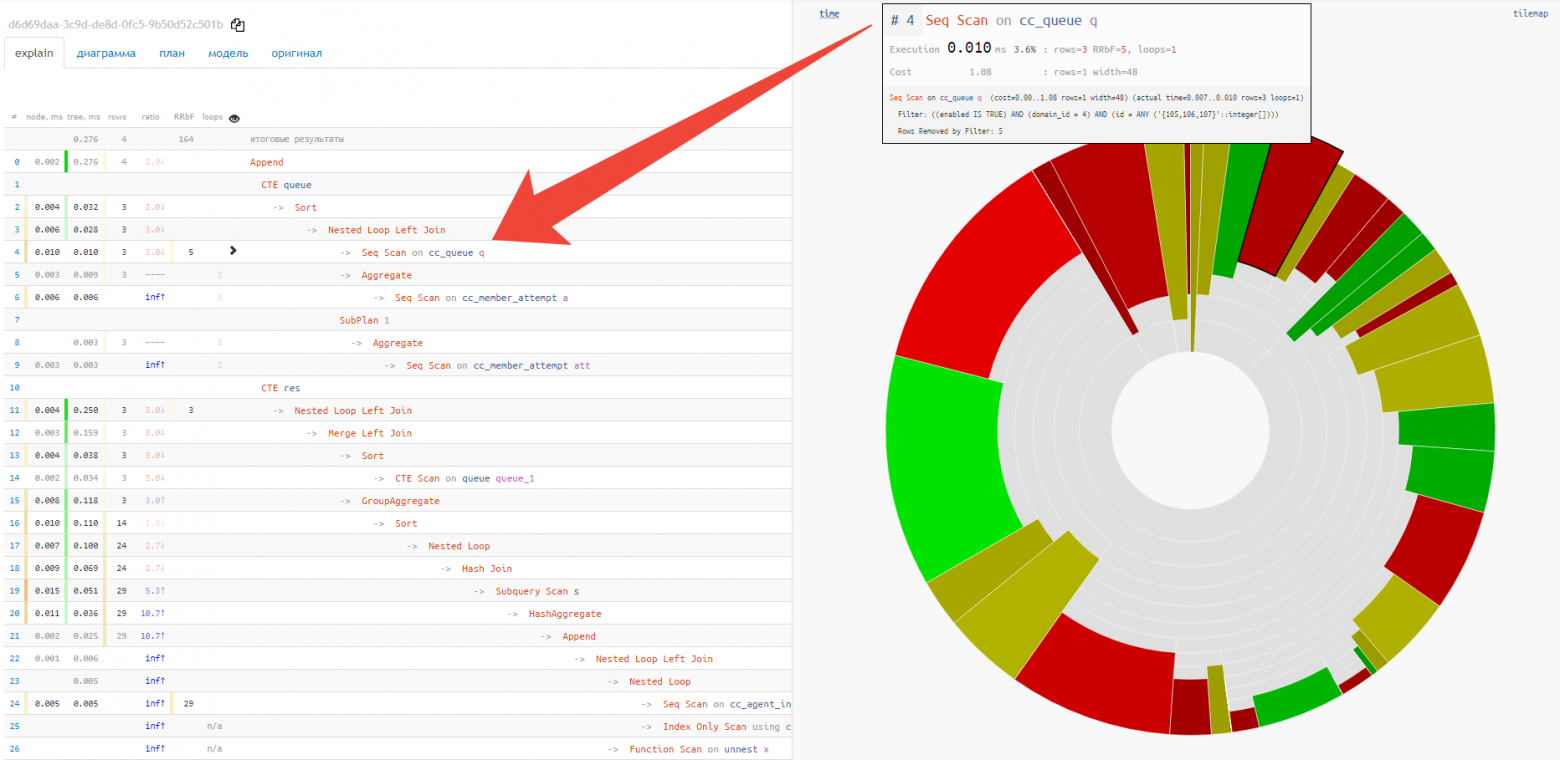
Круговая диаграмма [2]
Понять «где болит сильнее всего» непросто, особенно, если запрос содержит несколько десятков узлов, и даже сокращенная форма плана занимает 2-3 экрана. В этом случае на помощь придет круговая диаграмма:
Сразу, навскидку, видна примерная доля потребления ресурсов каждым из узлов. При наведении на него, слева в текстовом представлении мы увидим иконку у выбранного узла.
Плитка [1]
Круговая диаграмма плохо показывает отношения между разными узлами и «самые горячие» точки. Для этого гораздо лучше подойдет вариант отображения «плиткой»:
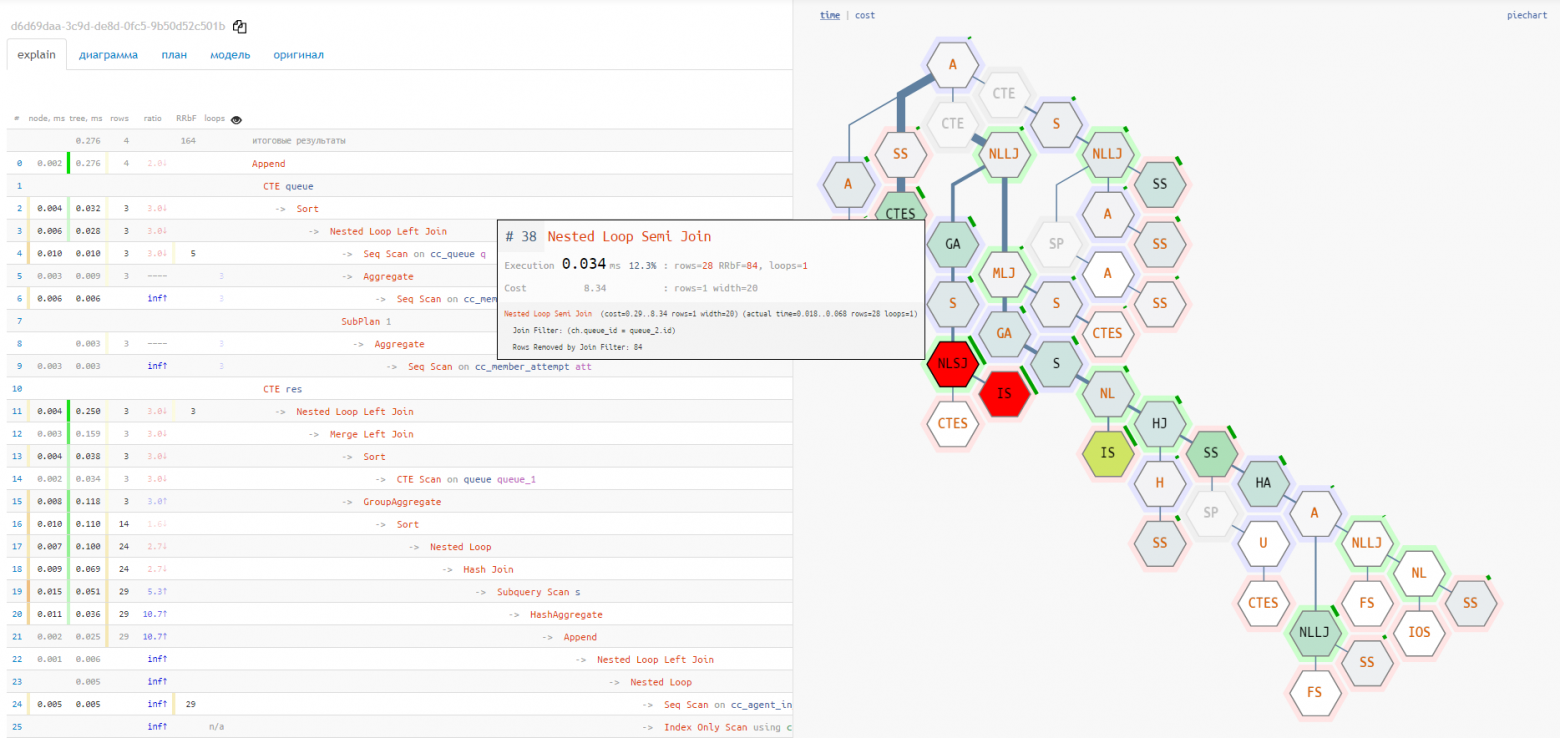
Диаграмма выполнения [2]
Оба предыдущих варианта не показывают полную цепочку вложений служебных узлов CTE/InitPlain/SubPlan — его можно увидеть только на диаграмме реального выполнения:
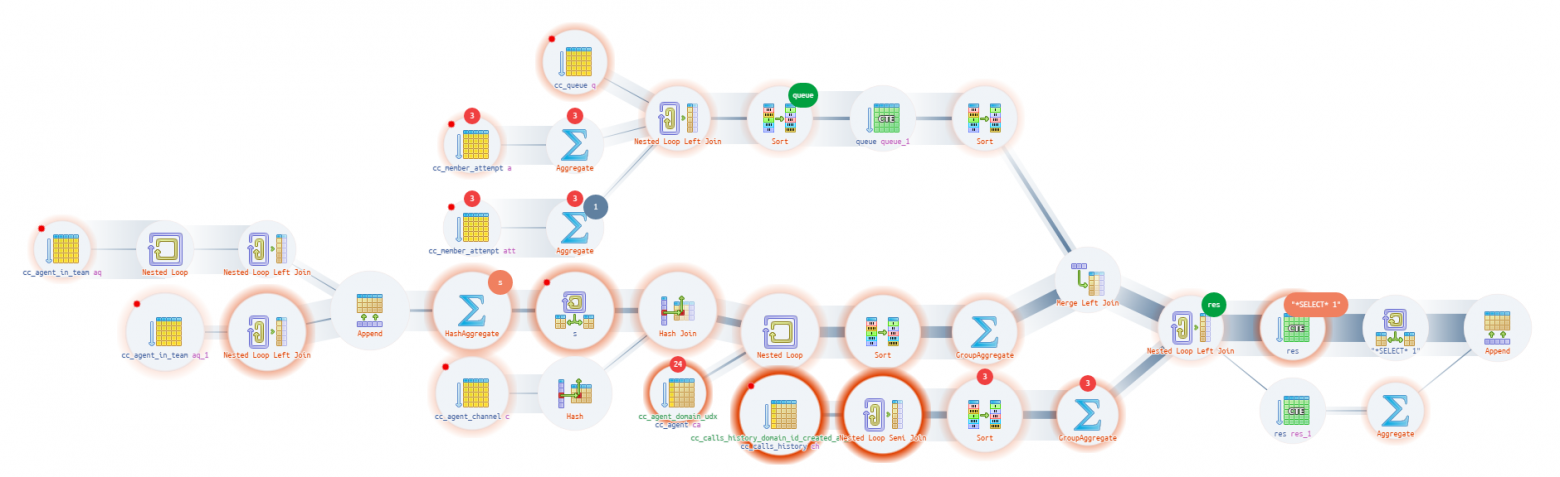
Источник